Dragonfly万向嘉年华演讲:去中心化推理对AI的重要性与挑战
本文介绍了AI与Web3结合的重要议题,Dragonfly Capital的创始合伙人Haseeb在会上发表了题为“Don’t Trust,Verify”的演讲,介绍了加密货币和人工智能交叉点上正在构建的智能合约网络。这些项目旨在通过智能合约实现去中心化的机器学习模型训练和推理,解决传统训练过程中高昂的成本和对中心化提供者的信任问题。然而,目前仍面临着成本高、验证困难等挑战。为了解决这些问题,可以尝试避免使用浮点数,但这会导致运行速度变慢或输出结果的误差。目前有人在探索使用新的受信任执行环境来解决这个问题,但仍处于早期阶段。尽管面临挑战,但AI和加密技术的结合仍是一个值得密切关注的重要领域。

原文作者:博文
原文来源:白露会客厅
AI 与 Web3 的结合,是本次香港 Web3 嘉年华的重要议题之一。Web3 在用户激励和资源分配上有着显著的优势;同时分布式的协作方式在算力、数据等方面可以为初创企业提供良好的支持。在监管压力日渐增大和资源垄断日渐严重的产业环境中,拥抱 Web3 的方式成为许多 AI 初创企业寻求破局之法的优先选择。
2024 年 4 月 7 日,DragonFly Capital 的创始合伙人 Haseeb 在香港 Web3 嘉年华会场发表了题为“Don't Trust, Verify” 的 AI+Web3 融合赛道发展的主旨演讲。Dragonfly Capital 成立于2018年,由冯波和 Haseeb Qureshi 共同创立,投资了包括 Maker、Compound、Near、Matter Labs、Celo 和 UMA 等在内的多个著名西方项目。自成立以来,Dragonfly Capital 已经完成了多轮融资,募集资金总额达到了数亿美元,吸引了包括老虎环球、KKR、红杉中国等知名投资机构的参与。
演讲重点分为两部分,首先介绍了三大类 Crypto x AI 项目:去中心化计算、去中心化训练和去中心化推理三个赛道的基本情况,并重点针对去中心化推理的重要性和仍需面对的挑战作出了分析解读。
 以下为演讲原文编译,内容略有删改。
以下为演讲原文编译,内容略有删改。
大家好。我是 Haseeb。我是 Dragonfly 的管理合伙人,Dragonfly 是一家全球性的加密货币投资公司。今天我要和大家谈谈加密货币和人工智能的交集。这是最近非常热门的一个领域。很多人都在谈论它。
作为一名投资者,我看到了很多来自不同初创公司的提案,它们试图在加密货币和人工智能的交叉点上构建一些东西。
所以今天的演讲会是一个概述,来看看人们正在构建的各种不同东西,以及他们为什么能够做得如此出色。
首先回答一个问题,为什么是加密货币和人工智能?
加密货币和人工智能之间的一个好处是,加密货币是一个建立信任的行业,而人工智能是一个非常需要信任的行业。因此,它们之间有很多有趣的交叉点,两者可以相互增强。
让我给大家概述一下,在加密货币和人工智能交叉点上,人们正在构建的智能合约网络,或者说去中心化网络的不同领域。
 Decentralized Compute
Decentralized Compute
首先是去中心化计算。这基本上是 GPU 市场。因为当然,GPU 是用来训练 AI 模型的。
目前全球范围内存在着大规模的 GPU 短缺。英伟达之所以是一家如此有价值的公司,部分原因是他们正在构建大部分人们用于机器学习的这些非常有价值的 GPU。如果你不能正常获得这些 GPU,也许你可以通过去中心化市场以比通过亚马逊或其中一个中心化云服务提供商更便宜的成本来获得它们。
这里有两个主要的网络,分别是 Render 和 akash。Render 的估值约为 50 亿美元,akash 略低于 10 亿美元。
Decentralized Compute
下面看第二类项目。首先你得到了 GPU,从一个去中心化的市场得到了 GPU。那么接下来,你需要训练一个模型。好的,这就是第二类:去中心化训练。
有一些不同的初创公司正在研究这个领域,但这是一个非常难以解决的领域,因为训练非常昂贵。你知道,在之前的谈话中听到过,一些公司在这些训练过程上花费了数百万美元。所以要完全以去中心化的方式做到这一点非常困难。
但如果你看一下 bittensor,它是今天最大的人工智能代币,价值约 120 亿美元,它的运作方式基本上是去中心化训练。你可以把它想象成一种去中心化的比赛,竞争训练一个在某个特定目标函数上具有最大性能的模型。
还有 gensyn,这是一家即将推出的初创公司,也在做去中心化训练。
Decentralized Compute
第三类是推理,也是我在本次演讲中要深入探讨的内容。推理是指你已经拥有了 GPU,对模型进行了训练,那么现在你想运行他;但是,你发现自己没有运行模型的能力,于是你使用一个去中心化网络来为你运行模型。Ritual、 Modulus等等许多不同的初创公司现在就在做这件事。
作为风投从业者,我最常见到的可能是人们在去中心化推理方面的工作。我们可以先简单介绍下,机器学习模型是如何工作的,了解一下训练模型时发生了什么可能会有所帮助。
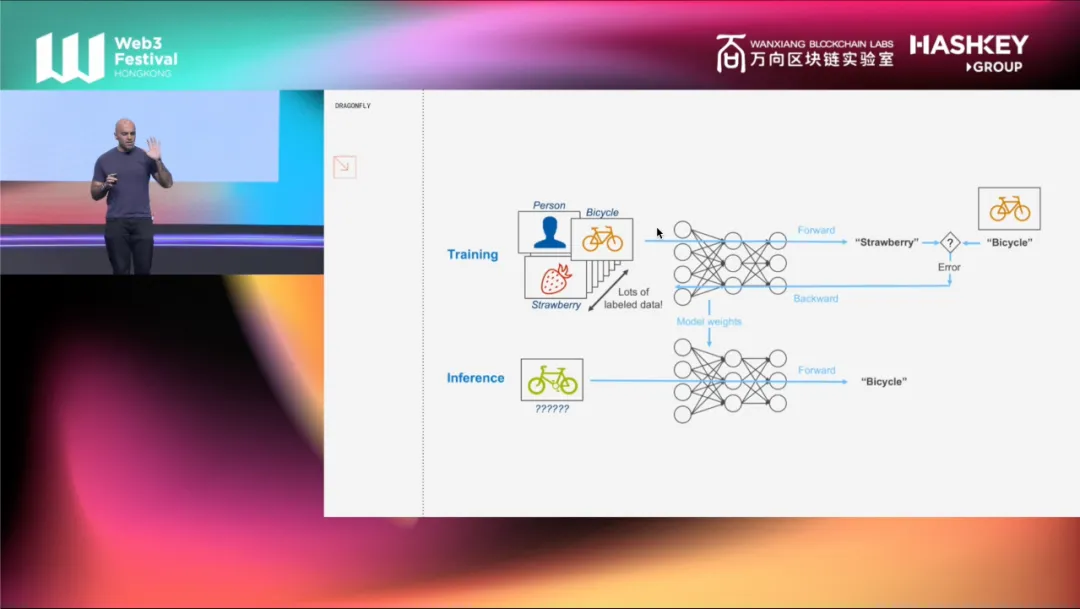 首先,你有很多数据,最好是有标记的数据。比如像图中所示,这是一辆车,这是一个人,这是一个草莓。一旦你有了所有这些标记的数据,就用它们来训练模型。每当你的模型犯了一个错误,你就更新模型的权重。这些都是模型的参数(parameters)或模型中的神经元(neurons)。你使用反向传播(Back-propagation)和梯度下降(gradient descent)来更新它们。训练的过程是所有这类的事情反复操作的过程。
首先,你有很多数据,最好是有标记的数据。比如像图中所示,这是一辆车,这是一个人,这是一个草莓。一旦你有了所有这些标记的数据,就用它们来训练模型。每当你的模型犯了一个错误,你就更新模型的权重。这些都是模型的参数(parameters)或模型中的神经元(neurons)。你使用反向传播(Back-propagation)和梯度下降(gradient descent)来更新它们。训练的过程是所有这类的事情反复操作的过程。
这些就是你支付数百万美元的理由。你惊喜运行一个庞大且复杂的训练过程,使用许多TB级别的数据对模型进行训练。然后,一旦你有了训练好的模型,你就可以进行推理,也就是你给它一张图片。
你向模型提问:这是什么?模型会施展它的魔法,然后说:哦,这是一辆自行车。好的,这一部分比训练要便宜得多,但要确实地获得良好的、快速的和一致的推理,对你拥有的模型来说仍然是非常重要的。
这里明确一下,Crypto 中还有其他更应用层的人工智能项目,比如像 MyShell 这样的聊天机器人,以及像 Kaito 这样的进行数据分析或查看交易指标的项目。但我将专注于纯粹的去中心化推理协议。
 我来解释为什么我专注于这一部分。假设你想运行一个非常流行的模型,比如由 Facebook 制作的 Llama2-70B。Llama2-70B 需要 140GB 的 RAM。大多数人都没有 140GB 的 RAM,对吧?即使你家里有一个 GPU,它可能也没有那么多的内存。
我来解释为什么我专注于这一部分。假设你想运行一个非常流行的模型,比如由 Facebook 制作的 Llama2-70B。Llama2-70B 需要 140GB 的 RAM。大多数人都没有 140GB 的 RAM,对吧?即使你家里有一个 GPU,它可能也没有那么多的内存。
 所以为了运行这样的模型,你需要别人为你运行,他们拥有比你更强大的计算机。现在你可能不想信任像 Sam 先生和他的公司这样的中心化提供者。但你仍需要能够信任输出结果,对吧?这时候,你可能选择了去中心化网络来做这件事。
所以为了运行这样的模型,你需要别人为你运行,他们拥有比你更强大的计算机。现在你可能不想信任像 Sam 先生和他的公司这样的中心化提供者。但你仍需要能够信任输出结果,对吧?这时候,你可能选择了去中心化网络来做这件事。
到这里没有结束,紧接着你又需要考虑一个新的问题:如果你在一个去中心化的网络上这样做,你怎么知道你实际上得到了 Llama2-70B?你可能得到的是LIama-70。它可能在欺骗你,实际上运行的是比你要求的更便宜的模型。
所以,每当你在一个去中心化网络上这样做时,你必须假设有人在欺骗你。你如何确保你不被欺骗?答案是你需要某种验证。如何验证?这时就是我们有选择的时候了:我们有智能合约。所以把机器学习模型放在智能合约中,运行智能合约,搞定。
好的,听起来很美好。但事实是这样做是行不通的:因为成本太高。
 GPT 三有一个隐藏层。嵌入大小是 12,288 个参数,200,012,288 个权重。在今天的以太坊上,这样大小的单个矩阵乘法运算将耗费 100 亿美元的 Gas。它将连续填充每个区块一个月之久,仅仅是一个单独的矩阵乘法运算。而在一个单独的机器学习推理中,有成千上万个这样的矩阵乘法运算。
GPT 三有一个隐藏层。嵌入大小是 12,288 个参数,200,012,288 个权重。在今天的以太坊上,这样大小的单个矩阵乘法运算将耗费 100 亿美元的 Gas。它将连续填充每个区块一个月之久,仅仅是一个单独的矩阵乘法运算。而在一个单独的机器学习推理中,有成千上万个这样的矩阵乘法运算。
这样行不通,对吧?所以我们必须找到一种比在区块链(主网)上全部运行更有效的方式,因此,人们采取了三种不同的方法来构建去中心化推理。
关于【Dragonfly万向嘉年华演讲:去中心化推理对AI的重要性与挑战】的延伸阅读
重新理解Marlin:AI下半场的可验证计算L0「新基建」
Marlin是一种可验证云计算服务,利用加密技术保证数据安全,为AI+Web3应用提供低延迟、低成本的解决方案。它基于TEE和ZKP技术,为用户提供通用化的云计算方案,并通过激励机制吸引节点为网络贡献资源。Marlin的愿景是成为AI世界的可验证通用L0,为Oracle预言机、ZK Prover系统、AI人工智能等应用场景提供节点算力和存储等网络资源服务。它可以为AI大模型训练提供安全的计算环境,并为多元化应用场景提供可验证计算中间件。在AI+Web3时代,Marlin有巨大的价值潜力,可能成为未来AI+Web3应用的关键基础设施。
Sam Altman 围绕 OpenAI 打造出一个致富帝国
OpenAI首席执行官奥特曼同时经营副业,但只有一份工作让他发了财。他投资了多家想抓住人工智能风口的公司,包括网络安全软件公司和清洁能源公司。他最成功的投资是支付处理初创公司Stripe。奥特曼也投资了使用OpenAI技术的初创公司。他曾因投资引发利益冲突而被罢免职务,但重新担任首席执行官后制定了新的利益冲突政策。董事会正在进行改革,包括强化利益冲突政策和独立审计委员会。奥特曼计划通过全面披露和董事会管理来解决利益冲突问题。
ZK ML
第一种方法被称为 ZK ML。你可能听说过零知识证明。这些是一种密码学魔法,可以非常高效地证明某人进行了这个计算。
但是,ZK ML 的问题是它非常慢。生成类似 LIama2-70B 这样的机器学习模型证明需要很长时间,而且成本很高。这可能导致零知识推理的成本大约是普通推理的 1000 倍。取决于模型的架构,可能更多。它运行速度的缓慢也是致命的,它的速度大约是运行一个普通模型所需时间的 1000 倍。
不过,优点是它非常安全。如果我在任何模型上运行零知识证明,你可以毫无疑问地知道,你确实按照你说的那样运行了机器学习模型。如果你愿意,你还可以保护隐私。有一些项目正在尝试这样做,比如 EZKL、GIZA、Modulus,但目前在大型模型上实施起来并不是很实用。
Cryptoeconomic ML
好,我们讨论下一种方法:加密经济学(Cryptoeconomic ML)。当讨论所谓区块链共识的时候,我们总会或多或少提到加密经济学。比如权益证明:每个人都会投票。A认为输出是这样的,B认为输出是那样的。我们所有人都有权益,我们投票并观察。但如果你与其他人不同,你就会受到惩罚。这就是利用加密经济学处理的方法。
这个方法一点都不花哨,实际上它根本没有使用人工智能的任何独特方面,只是将其视为一个典型的加密问题。如果 Chainlink 正在做机器学习,这可能就是他们会采取的方法。Ritual、Automa,这些都是采用加密经济学方法的网络。
加密经济学的优点是它快速、廉价、大多数安全,对吧?这取决于有多少权益。使用加密经济学,很容易快速启动并得到相对安全的东西。
那么如果采用这种方法需要支付多少成本呢?在加密经济学中,运行共识的所有节点也都必须运行计算。所以如果要推理这个东西是不是一辆自行车,所有的共识节点也都必须运行相同的模型,以确定他们是否同意它是一辆自行车。如果,假设有 20 个节点,那么你必须支付 20 倍的成本。所以不管有多少节点将进行加密经济学投票,你都必须支付所有节点来进行底层计算。
 Optimistic ML
Optimistic ML
第三种方法是 Optimistic ,介于这两种方法之间。Optimistic 机器学习基本上是:当有人回应说“好的,是一辆自行车。我运行了模型,它是一辆自行车。”我们会假设这是正确的。但如果它不正确,那么有人可以提交一个欺诈证明,证明这个人没有正确地运行模型。而你必须做的是等待,因为那个人可能作弊,你必须等待挑战期限到期。
这基本上是我今天看到的人们尝试构建这些去中心化推理网络的三种主要机制。有趣的是,这些并不新鲜。这些实际上是非常熟悉的机制,用于确定给定计算是否正确。比如 zkSync、Optimistic、和大多数 Layer1。这些是我们在加密领域常见,并且也可以用于机器学习的方法。
那么,不同之处是什么?
挑战一:调整模型为可证明系统
这时,我要提到的关于机器学习的第一件事是:机器学习并不是设计来被证明的。机器学习的设计目的基于训练的模型来追求快速。
 一个普通的机器学习模型可以表示为一个图。所有这些计算必须完成,所有这些不同的权重,不同的乘法正在发生。只要图是从左到右的,它们可以以任何顺序发生。当一个 GPU 执行这个图的过程时时,记住 GPU 有成千上万个核心。所以它们以一种高度并行的方式执行这个图中的流程,同时执行许多不同的分支,然后收集结果并继续前进。
一个普通的机器学习模型可以表示为一个图。所有这些计算必须完成,所有这些不同的权重,不同的乘法正在发生。只要图是从左到右的,它们可以以任何顺序发生。当一个 GPU 执行这个图的过程时时,记住 GPU 有成千上万个核心。所以它们以一种高度并行的方式执行这个图中的流程,同时执行许多不同的分支,然后收集结果并继续前进。
在这个超级并行的计算中,哪个分支先执行,哪个分支后执行并不重要。我只关心的是尽快完成所有的计算。
但如果你要进行程序验证,那么这种方法是行不通的。在程序验证中,你必须验证这些步骤是否按照指定顺序执行。如果你没有按照指定的顺序执行这些步骤,那么你就必须回头检查,看看你哪里出错了。所以你需要对非线性计算进行线性化。而这种线性化是昂贵的,它意味着你必须将机器学习模型编译成另一种格式,以供证明。
如果你将它编译成这种线性化的格式,那么现在在 GPU 上运行它的效率就会降低,因为 GPU 利用了并行性。如果你将所有内容展开成一个长的线性计算,那么 GPU 在运行这种线性化计算时就不会像之前那样有效了。
所以去中心化推理网络的第一个问题就是:必须将模型调整到一个可以进行证明的系统中。
挑战二:模型输出结果不可控
现在,假设我们有所有这些不同的节点,都运行 LIama2-70B 尝试得到关于这个事情的正确答案;或者运行运行另一种模型,比如 ImageNet。
问题在于,即使你们所有人都在运行相同的模型,你们可能会得到不同的输出。为什么?因为并非所有的 GPU 都执行相同的操作。不同的 GPU 架构可能会导致一些主要乘法的输出略有变化;甚至使用不同版本的 CUDA,比如没有更新你的操作系统,基本上意味着你最终得到了不同的结果,这很令人困扰。
相同的模型并不一定意味着相同的结果。因此,你的网络中的每个人都必须使用完全相同的模型和完全相同的架构,以确保他们实际上得到相同的输出。
挑战三:浮点数诅咒
第三件事是浮点数的诅咒。时间问题我们不能详细讨论,概括来说:浮点数不是可结合的。这意味着如果你以不同的顺序相加或相乘两个浮点数,你可能会得到不同的输出,这个输出可能会在整个模型的过程中。
这意味着即使核心执行的方式、执行所有这些并行计算的顺序,在同一架构、同一 GPU 中的每次运行中也可能略有不同。如果是一个运算过程,得到稍微不同的输出可能没有关系;但如果是分类器或生成图像,因为这些误差你得到的图像可能像素都会有区别。
怎么样规避这个问题?你必须避免使用浮点数。这很糟糕,因为在现代 GPU 上非常慢,要么你需要允许一些输出上的放宽。在 GPU 中有太多的不确定性,为了让两个 GPU 达成一致,你必须允许一小部分误差。
这些都是在正常编程验证中不会出现的不同实现细节。如果我在以太坊上做一个智能合约,这些都不是问题。以太坊甚至没有浮点数,因为以太坊知道浮点数是疯狂的。你绝对不应该在金融应用中使用它们。
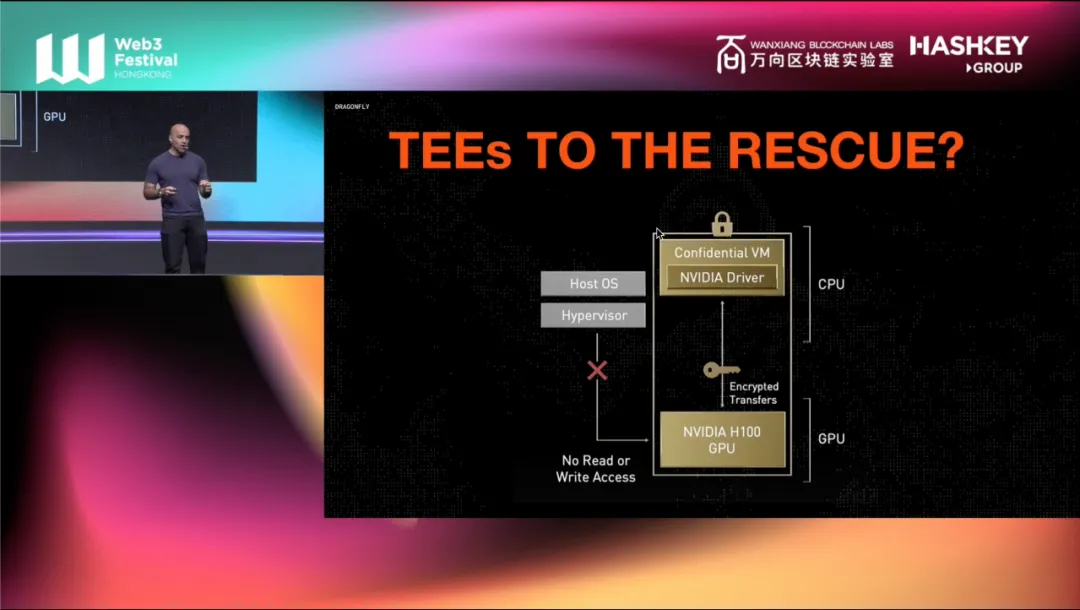
但在 GPU 中,浮点数是机器学习所做的一切。这就是为什么这非常困难。我没时间详细讨论这个问题,但许多人正在探索的一个新的有希望的领域或受信任的执行环境。
新一代的 NVIDIA GPU 配备了设备上的受信任执行环境,意味着现在你可以在 H100、B200 中进行机密计算。不过,这些只是最高端的型号。大多数人没有这些,而且它们仍然很新,所以目前使用它们的人并不多。但我认为这将是下一代协议,使用 TEE 来获得某种可验证性,甚至机密性的一个有希望的新领域。
 所以要记住的是,AI+Crypto 很重要。现在还处于早期阶段,而且非常困难,有很多问题需要解决。没人能保证这些任何一项会成功或有用,但这是一个非常有趣的领域,我鼓励大家密切关注。
所以要记住的是,AI+Crypto 很重要。现在还处于早期阶段,而且非常困难,有很多问题需要解决。没人能保证这些任何一项会成功或有用,但这是一个非常有趣的领域,我鼓励大家密切关注。
免责声明:本文仅代表作者个人观点,不代表链观CHAINLOOK立场,不承担法律责任。文章及观点也不构成投资意见。请用户理性看待市场风险,以及遵守所在国家和地区的相关法律法规。
图文来源:博文,如有侵权请联系删除。转载或引用请注明文章出处!
