万物创造营:AI大模型与Web3如何共生?
大模型产生后,算法、算力和数据被大企业垄断,私有数据耗尽和算力短缺是主要问题。区块链可通过保护隐私、激励数据标注和协作训练解决。推理计算可在单个GPU完成,区块链可解决算力问题。微调训练可利用空闲计算资源,区块链可激励参与者共同完成。大模型需要人类专家参与微调,可通过代币激励社区参与。区块链可解决数据隐私和保密性问题,加速训练,为创业公司提供参与大模型的机会。Bittensor和Autonolas是新的区块链项目,可加速训练和保护交易隐私。Edge Client架构解决方案认为个人应拥有边缘节点,区块链可实现节点间协作。区块链从业人员应参与大模型创业,让大模型属于整个人类。

原文作者:36C
原文来源:万物岛ThreeDAO
大模型行业问题以及如何结合Web3来解决问题
众所周知,2015年之后互联网行业进入了寡头垄断阶段,全球各国都对平台公司进行了反垄断审查。大模型的产生进一步加剧了寡头的垄断地位。大模型包括算法、算力和数据:
- 在算法领域,虽然存在一定程度的垄断,但是由于开源力量和研究大学的对抗,以及人们对于寡头的不信任,所以算法在很大程度上可以保持开放;
- 在算力方面,由于大模型的训练成本极高,算力只有大企业才能负担,所以这本质上导致了算法的生产完全被大企业控制;
- 在数据方面,虽然大模型的训练依靠的是公开数据,但是根据大模型的参数增长,公开数据很快将会耗尽,因此大模型的继续增长依赖于私有数据。虽然数量众多的小企业拥有的绝对数据量巨大,但是孤立存在难以利用,因此大企业仍然对数据具有垄断优势。
因此,大模型时代的中心化控制比以前更强,未来的世界很可能会被少数几台甚至一台计算机控制。(即便在去中心化的Web3世界,Vitalik建议的以太坊的End Game将会由一台巨大的出块机来运行。)
另外,开发ChatGPT的OpenAI公司的核心人员仅仅20余人。基于各种原因,ChatGPT的算法至今没有开源,原来基于非盈利的企业性质变更为有限盈利。随着依赖于ChatGPT的各种应用改变了人类生活,ChatGPT模型的一些修改将会极大的影响人类,相对于Google的不作恶原则,ChatGPT对人们的影响更加深入。
因此,模型的计算可信性将会成为重要议题。虽然OpenAI可以作为非盈利,但是权力被少数人控制仍然会产生很多不利后果。(对比之下,Vitalik建议的以太坊End Game虽然由一台机器出块,但是将通过公众非常容易的验证来维持透明性。)
同时对于大模型行业现在还存在:算力短缺,可用的训练数据即将消耗完,以及模型的共享等问题。根据统计,在2021年之前,人工智能行业的问题是缺乏数据,所有深度学习公司都在寻找垂直行业的数据;而在大模型之后,缺乏算力成为障碍。
大模型开发分为几个阶段:收集数据、数据预处理、模型训练、模型微调、部署查询推理。从这几个阶段,先简述下区块链对大模型的贡献,以及如何对抗大模型集中度过高的危害。
- 在数据方面,由于公开数据在2030年之后将被消耗完,更有价值更大数量的私有数据需要通过区块链技术保护隐私的前提下被利用;
- 在数据标注方面,可以通过代币激励更大规模的标注和核查数据;
- 在模型训练阶段,通过模型分享,协作训练来实现算力共享;
- 在模型微调阶段,可以通过代币激励社区的参与;
- 在用户查询推理计算阶段,区块链可以保护用户数据隐私。
 具体而言:
具体而言:
1)、稀缺的算力
算力是大模型的必要生产要素,而且是如今最贵的生产要素,以至于刚刚融资的创业公司不得不将80%的资金转手就交给NVIDIA购买GPU。自己生产大模型的公司不得不至少花费5000万美金自建数据中心,而小型创业公司不得不购买昂贵的云计算服务。
但是,短时间的大模型热度以及大模型本身对于计算资源的巨量消耗,已经大幅度超过了NVIDIA的供应能力。据统计,大模型对算力的需求每几个月就翻番,2012到2018年期间,算力需求增加了30万倍,大模型计算的成本每年就增加31倍。
对于中国的互联网企业,还不得不面对美国对于高端GPU的禁运。可以说,巨额的训练成本是大模型技术被少数人控制的核心原因。
那么如何通过区块链化解大模型算力问题?
考虑大模型的生产主要分为大模型训练、微调训练(fine tuning)和用户查询推理计算。虽然大模型以训练费用昂贵著称,但是大模型一个版本只需要生成一次。大多数时间,对于大模型服务用户,只需要推理计算。根据AWS的统计也证实了这一点,80%的算力实际消耗在了推理计算。
虽然大模型的训练需要GPU之间的高速通信能力,无法在网络上完成(除非选择用时间延长换取低成本)。但是推理计算可以在单个GPU上完成。微调训练(fine tuning)是因为基于已经生成的大模型,赋予专业数据,因此需要的计算资源相对于大模型训练也要少很多。
在图形渲染方面,显然消费者GPU的性能要好于企业GPU,而且大多数时间在空闲。自从1999年加州伯克利大学发起寻找外星人的SETI,以及2000年流行的Grid Computing就已开始,有一些技术架构是利用空闲的计算资源协作共同完成一些巨量计算任务。在区块链产生之前,这些协作通常集中于科学任务,依赖参与者的热情和公益参与,限制了影响范围。现在利用区块链技术,可以通过代币激励其大范围的应用。
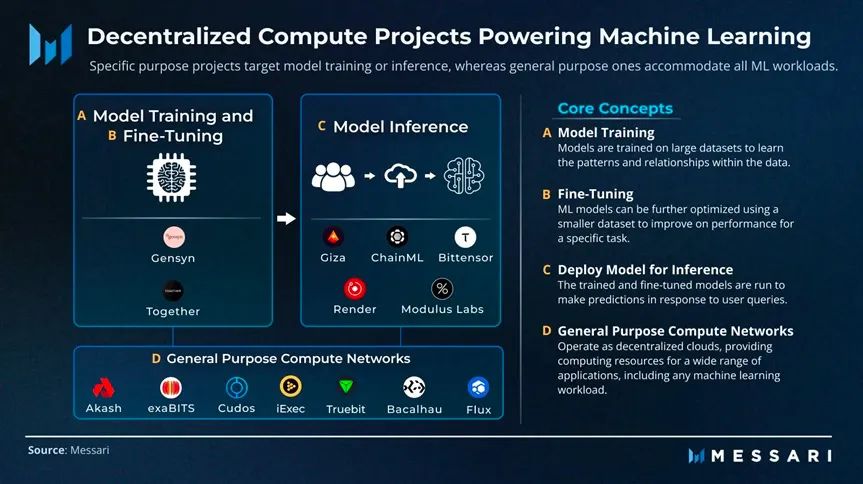
正如去中心化的云计算项目Akash,建立了一个通用计算网络,使用者可以部署机器学习模型用来推理计算以及渲染图片。还有Bittensor、Modulus Lab、Giza、ChainML等区块链结合AI的项目都针对查询推理计算。
而区块链 AI 计算协议Gensyn和开源生成式AI平台Together立志建立一个为大模型训练服务的去中心化计算网络。
挑战:对于去中心化的计算网络,难处不仅仅在于低速不可靠的通信网络,计算状态无法同步,处理多种类型的GPU类型计算环境,还要处理经济激励,参与者作弊,工作量证明,安全,隐私保护,以及反垃圾攻击等问题。
2)、稀缺的数据以及数据校正
大模型的核心算法Reinforcement Learning from Human Feedback(RLHF)需要人的参与微调训练,纠正错误、消除偏见和有害信息。OpenAI利用RLHF微调GPT3生成了ChatGPT,这个过程中OpenAI从Facebook的Group中寻找专家,支付每小时2美元给肯尼亚劳工。优化训练通常需要人类专家参与专业领域的数据,而其实现完全可以与通过代币激励社区参与的方式来结合。
Decentralized Physical Infrastructure Networks (DePINs) 行业通过代币激励人们按照感应器,共享来自物理世界的真实的、实时的数据,用以各种模型训练。包括:React收集能源使用数据、DIMO收集车辆行驶数据、WeatherXM收集天气数据,Hivemapper通过代币激励收集地图数据,激励人们对交通标志进行标注,帮助其RLHF的机器学习算法提高精确度。
同时随着大模型参数的增加,现存的公开数据将在2030年耗尽,大模型的继续进步将不得不依赖私有数据。私有数据的数量是公有数据的10倍,但是分散在企业和个人的手里,并且具有隐私和保密性质,难以被利用。产生了双难问题,一方面大模型需要数据,可有数据的一方虽然需要大模型,但是不希望将数据交给大模型使用。 这个双难问题同样可以通过区块链领域的技术来解决。
对于开源的推理模型,因为所需计算资源少,可以将模型下载到数据段来执行;对于不公开的模型或者大模型,需要将数据脱敏处理后上传给模型端。脱敏处理的方法包括合成数据和零知识证明。
不管是模型下载到数据端,还是数据上传到模型端,都需要解决权威性问题,防止模型或者数据作弊。
挑战:虽然Web3的代币激励可以协助解决这个问题,但是需要解决作弊的问题。
3)、模型协作
在全球最大的AI绘画模型分享平台—Civitai社区,人们共享模型,可以轻松地拷贝一个模型并且加以修改后生成符合自己要求的模型。
关于【万物创造营:AI大模型与Web3如何共生?】的延伸阅读
重新理解Marlin:AI下半场的可验证计算L0「新基建」
Marlin是一种可验证云计算服务,利用加密技术保证数据安全,为AI+Web3应用提供低延迟、低成本的解决方案。它基于TEE和ZKP技术,为用户提供通用化的云计算方案,并通过激励机制吸引节点为网络贡献资源。Marlin的愿景是成为AI世界的可验证通用L0,为Oracle预言机、ZK Prover系统、AI人工智能等应用场景提供节点算力和存储等网络资源服务。它可以为AI大模型训练提供安全的计算环境,并为多元化应用场景提供可验证计算中间件。在AI+Web3时代,Marlin有巨大的价值潜力,可能成为未来AI+Web3应用的关键基础设施。
Sam Altman 围绕 OpenAI 打造出一个致富帝国
OpenAI首席执行官奥特曼同时经营副业,但只有一份工作让他发了财。他投资了多家想抓住人工智能风口的公司,包括网络安全软件公司和清洁能源公司。他最成功的投资是支付处理初创公司Stripe。奥特曼也投资了使用OpenAI技术的初创公司。他曾因投资引发利益冲突而被罢免职务,但重新担任首席执行官后制定了新的利益冲突政策。董事会正在进行改革,包括强化利益冲突政策和独立审计委员会。奥特曼计划通过全面披露和董事会管理来解决利益冲突问题。
开源AI 新秀、双共识区块链项目Bittensor设计了一套代币激励去中心化的模型,基于mixture of experts协作机制,共同产出一个解决问题的模型,并且支持knowledge distillation,模型之间可以分享信息,加速训练,这为众多的创业公司提供了参与大模型的机会。
而作为自动化、预言机与共有 AI 等链下服务的统一网络,Autonolas设计了Agent与Agent之间通过Tendermint来达成共识的协作框架。
挑战:很多模型的训练仍然需要大量的通信,分布式训练的可靠性和时间效率仍然是个巨大障碍;
大模型和Web3的创新型结合上面论述了如何利用Web3解决大模型行业中存在的一些问题。两个重要力量的结合,将会产生一些创新性应用。
1)、利用ChatGPT编写智能合约
最近一个NFT的艺术家在没有任何编程知识的前提下,利用prompt操作ChatGPT发布了自己的智能合约,发行了代币Turboner,这位艺术家用YouTube记录了自己一个星期的创造过程,激发了大家利用ChatGPT参与智能合约创作。
2)、加密支付赋能智能管理
大模型的发展极大提高了智能助理的智能性,结合加密支付,智能助理将能够在智能助理市场上协调更多的资源,协作完成更多的任务。AutoGPT展示了依赖于用户提供的信用卡,他可以帮助用户自动购买云计算资源和订机票,但是受限于自动登录或者其他安全认证,AutoGPT的能力受到了极大限制。包括Contract Net Protocol在内的Multi Agent System(MAS)设计包括了多个智能助理在开放市场上的协作,如果在代币的支持下,这样的协作就会突破基于信任的有限协作,成为更大规模的基于市场经济的协作,就像人类社会从原始社会进入货币社会。
3)、zkML(Zero Knowledge Machine Learning)
zkp(Zero Knowledge Proof)技术在区块链方面的应用分为两类,一类是解决区块链的性能,通过将计算需求转移到链下,然后通过zkp到链上认证;第二类是用来保护交易隐私。zkp在大模型方面的应用包括模型可信计算(证明模型计算的一致性和真实性)和训练数据的隐私计算。在去中心化的环境中,模型的服务提供方需要向客户证明销售的模型是向客户承诺的模型,没有偷工减料;对于训练数据的合作方,需要在保护自己隐私的前提下参与训练或者使用模型。虽然zkp提供了一些可能性,但是仍然存在很多挑战,同态计算和联邦隐私计算等解决方案仍然不成熟。
基于BEC(Blockchain Edge Client)架构的解决方案
除了以上的流派之外,还有一个流派由于没有代币激励以及采用极简区块链应用,因此没有受到广泛关注。
基于BEC的架构在很多方面和Jack Dorsey提到的Web5的概念,以及Tim Berners-Lee的Solid有很多相似之处。
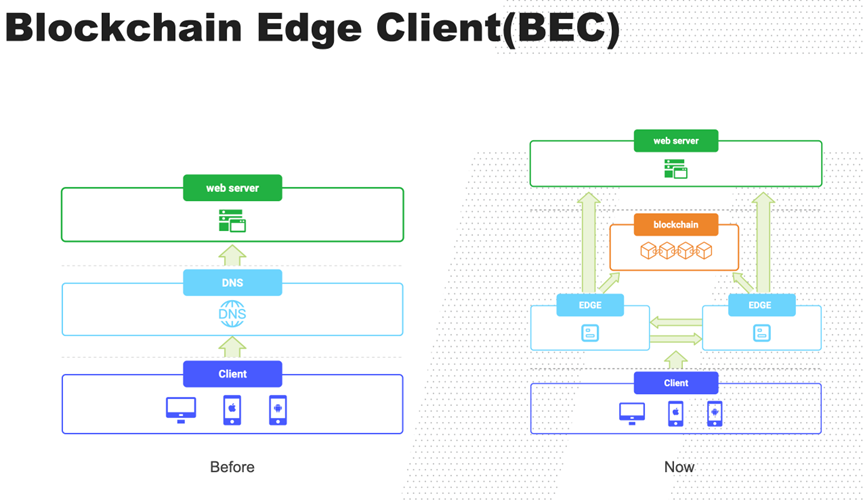
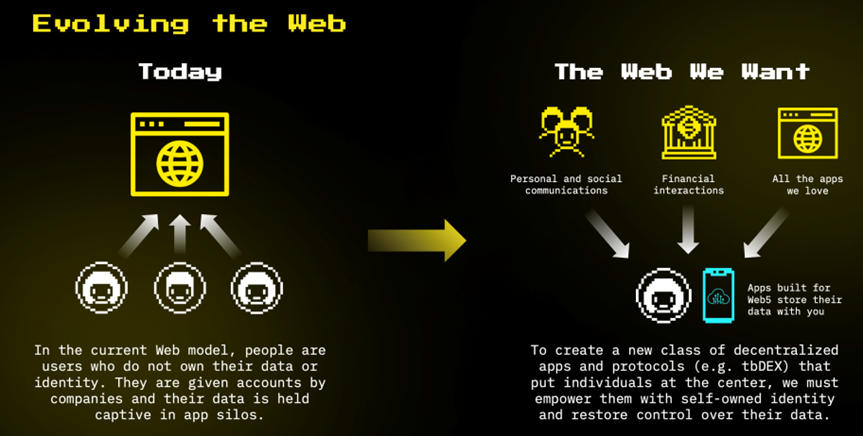
他们都认为:
- 每个人都有一个相对应的控制的边缘节点;
- 绝大多数应用场景的计算和存储都应该放在边缘节点处理;
- 个人节点与个人节点之间的协作通过区块链来完成;
- 节点与节点之间的通信通过P2P完成;
- 个人可以单独完全控制自己的节点或者委托信任的人委托管理节点(在有些场景下被称为relay server);
- 实现了最大可能的去中心化;
当这个与每个人对应的,由个人控制的节点存储了个人数据,加载了大模型,就可以训练出来完全个性化的,100%隐私保护的个人智能代理(Agent),SIG的中国创始合伙人龚挺博士浪漫的比喻未来的个人节点为《冰雪奇缘》里面雪宝头顶那朵一直跟随的个人云。
这样,现在元宇宙里面的Avatar将不再是键盘控制的形象,而是拥有了灵魂的agent,他可以代替我们24小时不间断的学习网络新闻,处理邮件,甚至可以自动回复你的社交聊天信息(絮絮叨叨的女朋友注意了,以后可能需要一种手段检测自己的男朋友是不是在利用agent敷衍自己)。当你的agent需要新的技能的时候,就像手机安装app一样,你可以在自己的节点里面安装新的app。
总结
历史上,伴随着互联网发展的不断平台化,虽然诞生独角兽企业的时间越来越短,但是本质上对于创业企业的发展却越来越不利。
伴随着Google和Facebook提供的高效内容分发平台,诞生于2005年的Youtube仅仅一年之后就被Google以16亿美金收购;
伴随着苹果应用商店的高效应用程序分发平台,成立于2012年的Instagram仅仅由10多人组成,于2012年被Facebook以10亿美金收购;
在ChatGPT大模型的支持下,仅仅有11人的Midjourney就一年赚了一亿美金。而仅仅有不超过100人的OpenAI估值超过200亿美金。
互联网平台公司越来越强大,大模型的产生并没有改变现有的互联网被大型企业垄断的格局。大模型的三要素,算法,数据和算力仍然被大企业垄断,创业公司没有能力创新大模型和没有资金实力训练大模型,只能集中在基于大模型对于垂直领域的应用。虽然大模型貌似促进了知识的普及,但是真正的力量被控制在全球不超过100人有生产模型能力的人手里。
如果未来大模型渗透到人生活的各个方面,你询问ChatGPT你的日常饮食,你的健康状况,你的工作邮件,你的律师函,那么理论上掌握大模型这些人只需要偷偷改动一些参数,就能极大的影响无数人的生活。大模型让一部分失业也许可以通过UBI或者Worldcoin解决,但是大模型被少数人控制产生的作恶可能性的后果更加严重。这是OpenAI建立的初心,OpenAI虽然通过非盈利的办法解决了盈利驱动的问题,但是如何解决权力驱动的问题呢?显然,大模型利用人类数十年积累的免费分享在互联网上面的知识快速训练了知识模型,但是这个模型却被控制在极少数人手里。
所以说,大模型和区块链在价值观方面有着巨大的冲突。区块链从业人员需要参与到大模型创业,用区块链技术解决大模型的问题。如果互联网上免费可得的巨量数据是人类共同所有的知识,那么依靠这些数据生成的大模型应该属于整个人类。就像最近OpenAI开始对文献数据库支付费用一样,OpenAI一样需要对你我奉献的个人博客支付费用。
免责声明:本文仅代表作者个人观点,不代表链观CHAINLOOK立场,不承担法律责任。文章及观点也不构成投资意见。请用户理性看待市场风险,以及遵守所在国家和地区的相关法律法规。
图文来源:36C,如有侵权请联系删除。转载或引用请注明文章出处!
