uniswap v3 数据清洗流程
本文介绍了如何通过pool的event log获取LP行为信息,以及如何计算position的净值和收益率。同时,还讨论了如何推测2023年1月1日之前的操作,以及如何处理资金转入转出的情况。最后,提出了一种细化每分钟收益率算法的尝试。作者还讨论了Uniswap LP的复杂性和特殊情况,并提出了解决方案。通过这些步骤,可以得到用户具体的投资行为。

原文作者:Zelos
原文来源:Antalpha Labs
Introduction
上一期, 我们从用户地址的角度, 统计了用户在 uniswap 上的净值和收益率。这次, 我们的目标依然如此。但要将这些地址所持有的现金统计进来。得到一个总的净值和收益率。
此次的统计对象有两个池子,包括
- polygon 上的 usdc-weth(fee:0.05), pool address: 0x45dda9cb7c25131df268515131f647d726f50608[1], 这也是上次分析所用的池子
- ethereum 上的 usdc-eth(fee:0.05), pool address: 0x88e6A0c2dDD26FEEb64F039a2c41296FcB3f5640[2],由于这个池包含native token,为数据处理带来了一些麻烦
最终得到的数据是小时级别的数据,注意: 每行的数据代表这个小时最后时刻的值.
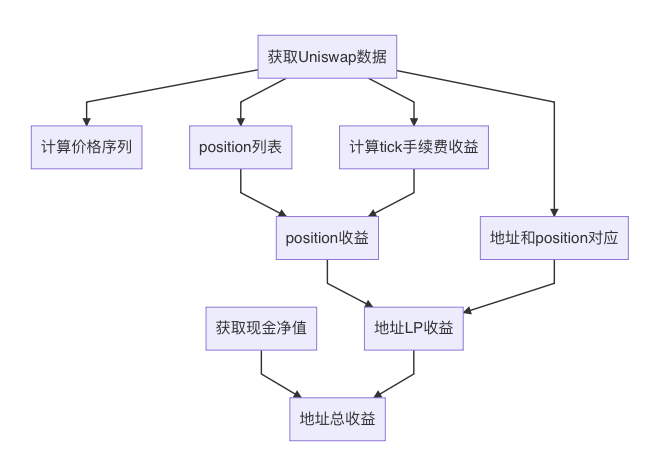
总体流程
- 获取uniswap的数据
- 获取用户现金数据
- 计算价格序列, 也就是 eth 的价格.
- 获取每分钟, 每个 tick 上获取了多少手续费
- 获取统计周期内, 所有 position 的列表
- 获取地址和 position 的对应关系
- 计算每个 position 的收益率
- 基于 position 和地址的对应关系, 计算每个用户地址作为 LP 的收益率
- 将用户的现金和 LP 合并, 并计算总体收益率
1. 获取Uniswap的数据
之前为了给 demeter 提供数据源, 我们开发了 demeter-fetch 工具. 这个工具可以从不同渠道获取 Uniswap pool 的 log, 并解析为不同格式. 支持的数据源有:
- ethereum rpc: eth客户端的标准rpc接口. 获取数据效率比较低. 需要多开一些线程.
- Google BigQuery: 从BigQuery的数据集下载数据. 虽然每天更新一次, 但对于胜在使用方便, 价格便宜.
- Trueblocks chifra: Chifra服务可以scrape链上的交易, 并重新组织. 从而轻松的导出交易, 余额等信息. 但这需要自己搭建节点和服务.
输出的格式包括:
- minute: 将 uniswap swap 的交易信息, 重采样为每分钟的数据. 用于回测
- tick: 记录 Pool 中每一笔交易. 包括 swap 和对流动性的操作.
这次我们主要获取 tick 数据, 用于统计 position 的信息, 包括资金量/每分钟收益/生命周期/持有人等.
这些数据是通过 pool 的 event log 获取的. 如 mint, burn, collect. swap. 但是 pool 的 log 并不包含 token id. 这让我们无法定位到 pool 的操作是针对那个 position 的.
实际上, uniswap LP 的权益是通过 nft 来管理的, 而这些 nft token 的管理人是 proxy 合约, token id 只存在于 proxy 的 event log 中. 因此如果想获取完整的 LP position 信息, 就要获取 proxy 的 event log, 然后与 pool 的 event log 结合起来.
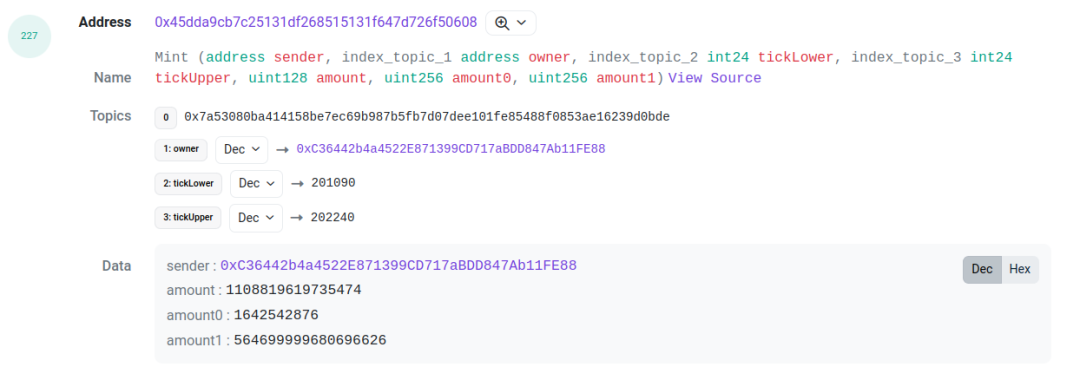
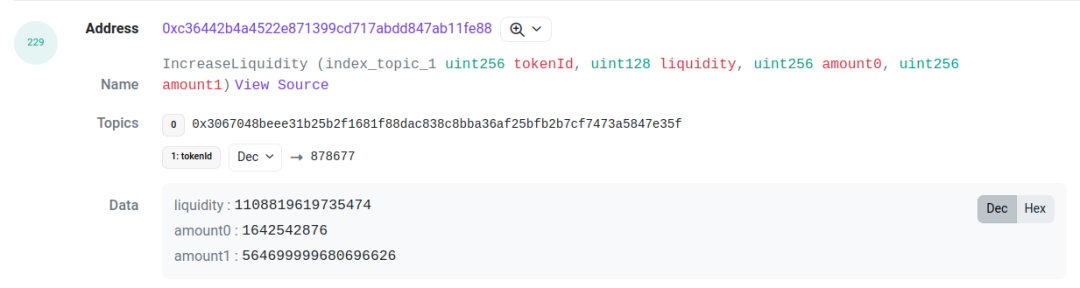
以这个交易[3]为例, 我们需要关注 log index 为 227 和 229 的两个 log. 它们分别是 pool 合约抛出的 mint 和 proxy 合约抛出的 IncreaseLiquidity. 他们之间的 amount(也就是 liquidity ), amount0 和 amount1 是一样的. 这可以作为关联的依据. 通过将这两个 log 关联起来, 我们可以得到这个 LP 行为的 tick range, liquidity, token id, 以及两种 token 对应的金额.
而对于高级用户, 尤其是一些基金, 他们会选择绕过 proxy, 直接操作 pool 合约. 这种情况下, position 不会有 token id. 这种情况下, 我们会用address-LowerTick-UpperTick的格式, 给这个 LP position 创造一个 id.
对于 burn 和 collect, 也可以用这种方式为 pool 的 event 找到对应的 position id. 但是这里有个麻烦, 有时候两个 event 的金额并不相同, 会有一点点偏差. 比如这个交易
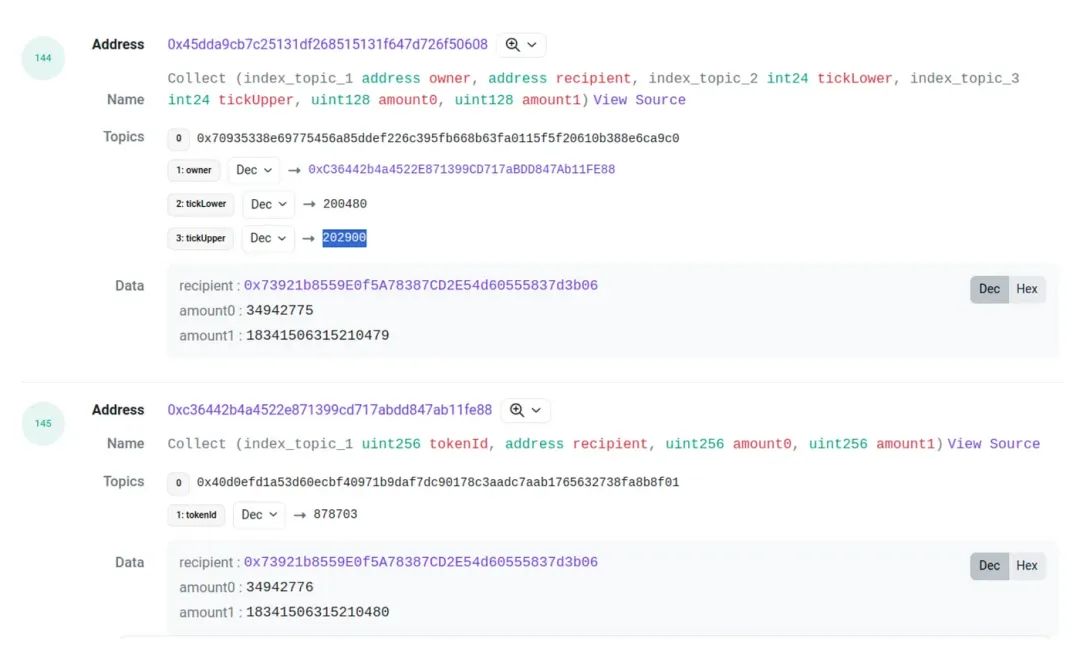 他的 amount0 和 amount1 会有一点小的差值, 这种情况虽然很少, 但也很常见. 所以我们在匹配 burn 和 collect 的时候, 给数值留了一些容错空间.
他的 amount0 和 amount1 会有一点小的差值, 这种情况虽然很少, 但也很常见. 所以我们在匹配 burn 和 collect 的时候, 给数值留了一些容错空间.
下一个要处理的问题是, 这个交易是谁发起的. 对于撤仓来说, 我们会把 collect 事件中的 receipt 作为 position 的持有人. 而对于 mint, 只能从 pool mint event 中得到 sender(见带有 mint event 的图).
如果用户是操作 pool 合约, 这个 sender 就会是 LP provider, 但如果是普通用户, 通过 proxy 操作合约, 这个 sender 会是 proxy 的地址, 这是因为资金确实是从 proxy 转到 pool 的. 但好在 proxy 会有 nft token 的产生. 而这个 nft token, 一定会转移给 LP provider. 因此, 检测 proxy 合约(也就是 nft token 的合约)的 transfer, 就可以查找到这个 mint 所对应的 LP provider
另外如果 nft 进行了转让, 会让 position 的持有人产生变化. 我们对此进行了统计, 这种情况较少. 为了简化, 我们没有考虑 mint 之后的 nft 转移.
2. 获取地址持有的现金
这个阶段的目标, 是获取一个地址在统计期间, 每个时刻所持有 token 的数量. 要实现这个目标, 需要获取两方面的数据,
- 地址在起始时刻的余额
- 地址在统计期间的转帐记录.
使用转帐记录对余额进行加减, 就可以推断出每个时刻的余额.
对于起始时刻的余额, 可以通过 rpc 接口查询. 在使用 achieve node 的情况下, 可以在查询参数中设置高度获取查询任意时间的余额. 对于 native token 和 erc20 的余额, 都可以用这种方式获取.
获取 erc20 的转帐记录比较轻松, 可以通过任意渠道(big query, rpc, chifra)获取.
而 eth 的转帐记录, 需要通过交易和 trace 获取. 交易还好, 但是查询和处理 trace 的运算量非常大. 幸好 chifra 提供了导出 eth 余额的功能. 可以在余额发生改变的时候输出一条记录, 虽然只能记录数量变化, 而不能记录转帐对象, 但也能满足要求. 这是合乎要求的成本最低的方法.
3. 价格的获取
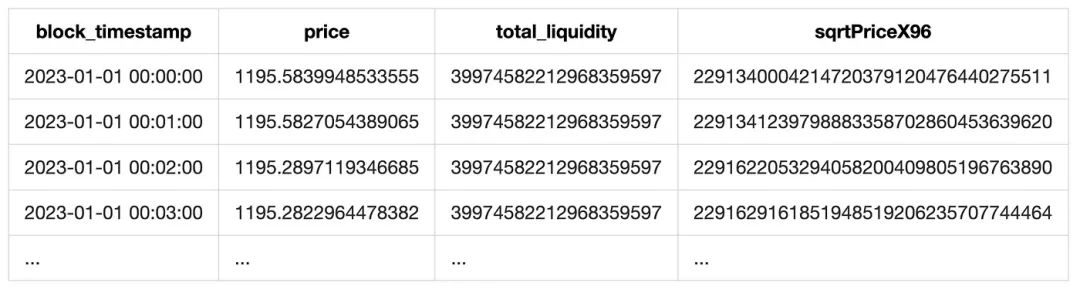
Uniswap 是一个交易所, 如果一笔 token 兑换发生, 会产生一个 swap event, 我们可以从 sqrtPriceX96 字段获取 token 的价格. 从 liquidity 字段获取当时的总流动性.
由于我们的池子都有一个稳定币, 所以获取对u的价格就非常容易. 但这个价格并不是绝对准确的. 首先他受交易频次的影响, 如果没有 swap 交易, 这个价格就会滞后. 另外, 稳定币脱锚的时候, 这个价格与对u的价格也会产生差距. 但就通常情况来说, 这个价格已经足够准确, 对市场研究来说并没有问题.
最后, 将 token 价格重采样, 就可以得到每分钟价格列表.
另外由于 event 的 liquidity 字段也包含了当前池子的总流动性, 我们将总流动性也顺便加入进来. 最终形成一张如下的表格:
 4. 手续费统计
4. 手续费统计
手续费是 position 的主要收入来源. 每次有用户在池上进行 swap 操作. 对应的 position 就能够收到一定的手续费(就是 lower 和 upper 包含当前 tick 的 position), 收益的金额与流动性的占比, pool 的手续费费率, 以及 tick range 有关.
为了统计用户的手续费收入, 我们可以将池子每分钟, 在哪个 tick 上, 发生了多少金额的 swap 记录下来. 然后计算当前分钟在这个 tick 上的手续费收益:
 最终成一张这样的表
最终成一张这样的表
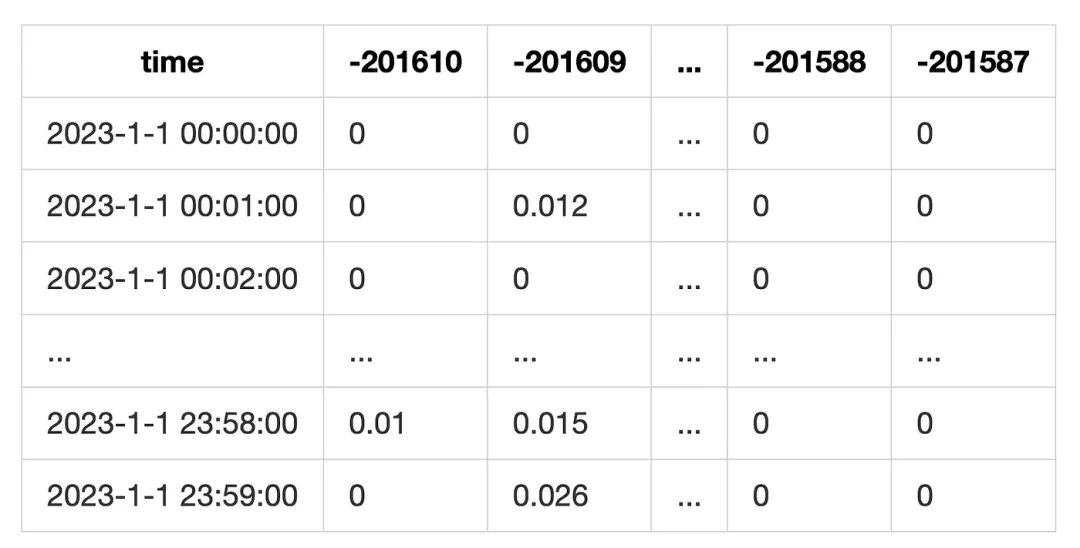 这种统计方式没有考虑 swap 的时候, 当前 tick 流动性用尽的情况. 但由于我们统计的目标是 lp, 也就是用 tick range 来进行统计. 这个误差可以得到一定的缓解.
这种统计方式没有考虑 swap 的时候, 当前 tick 流动性用尽的情况. 但由于我们统计的目标是 lp, 也就是用 tick range 来进行统计. 这个误差可以得到一定的缓解.
5. 获取 position 列表
获取 position 的列表, 首先要指定 position 的标识.
- 对于通过 Proxy 投资的 LP, 每个 position 都会拥有一个 nft, 也就是拥有一个 token id, 这可以作为 position 的 id.
- 而对于直接操作 pool 投资的 LP, 我们会为他编造一个 id, 格式为address_LowerTick_UpperTick. 这样, 所有的 position 都有了自己的标识.
通过这个标识, 我们可以将 LP 的所有操作整合起来. 形成一个描述 position 全生命周期的列表. 如
 但是需要注意的是, 这次统计的对象, 是 2023 年间, 而不是从池子创立开始, 不可避免的, 对于某些 position, 我们无法获取他们在 2023 年 1 月 1 日之前的操作. 这就需要我们推测在统计开始时, 这个 position 有多少 liquidity. 我们采取了一种经济的方式来推测:
但是需要注意的是, 这次统计的对象, 是 2023 年间, 而不是从池子创立开始, 不可避免的, 对于某些 position, 我们无法获取他们在 2023 年 1 月 1 日之前的操作. 这就需要我们推测在统计开始时, 这个 position 有多少 liquidity. 我们采取了一种经济的方式来推测:
- 将 mint 和 burn 的 liquidity 相加, 得到一个数字 L
- 如果 L>0, 也就是 mint>burn, 认为在统计开始之前, 就有了一些流动性, 此时会在统计开始的时刻(2023.1.1 0:0:0)补偿一个 mint 操作.
- 如果 L<0, 认为在统计结束的时候, 仍然持有 liquidity.
这种方式能够避免下载 2023 年之前的数据, 从而节约成本. 但是会面临沉没流动性的问题, 也就是:如果 LP 在这一年没有做任何操作, 是无法找到这个 LP 的, 但是这个问题并不严重. 由于统计周期是一年, 我们假定用户一般会在这期间调整 LP. 因为在一年的时间跨度, eth 的价格会发生很大的变化, 而且用户有非常多的理由调整他们的 LP. 如价格超出了 tick range, 把资金投入到其它 DEFI 等. 因此作为一个活跃用户, 一定会根据价格调整自己的 LP. 而对于那些将资金沉淀在 pool 中, 从来不调整的, 我们认为这个用户是不活跃的, 不在统计范围内.
而另一种更麻烦的情况是, position 在 2023 年之前 mint 了一些 liquidity, 然后在周期内又进行了一些 mint/burn 的操作, 到统计结束, 也没有 burn 掉所有的流动性. 因此我们只能统计到一部分的流动性. 这种情况下, 沉没流动性会对 position 的手续费估算造成影响, 造成收益率异常. 具体原因后面再讨论.
在最终的统计中, polygon 一共有 73278 个 position, 而 ethereum 有 21210 个 position, 每个链收益率异常的不超过 10 个, 证明这个假定是可信的.
6. 获取地址和 position 的对应关系
由于我们统计的最终目标是地址的收益, 因此还要获取地址和 position 的对应关系. 通过这个关联, 就可以得到用户具体的投资行为.
在步骤 1 中, 我们做了一些工作找到资金操作(mint/collect)的关联用户. 因此, 只要找到 mint 的 sender 和 collect 的 receipt, 就可以找到 position 和地址的对应关系
7. 计算 position 的净值和收益率
在这个步骤中, 我们要计算每一个 position 的净值, 再根据净值求出收益率
净值
Position 的净值包含两部分, 一个是 LP 的 liquidity, 这部分相当于做市的本金. 用户将资金投入 Position 后, liquidity 的数量不会变化, 但是净值会随着价格变化而产生波动. 另一部分手续费收益, 这部分独立于 liquidity, 单独存放在 fee0 和 fee1 两个字段中. 手续费净值随着时间增长而增多.
因此在任意分钟, liquidity 与这分钟的价格结合, 就可以得到本金部分的净值. 而手续费的计算, 需要用到第四步所计算的手续费表.
首先用这个 position 的 liquidity, 除以当前池子的总 liquidity, 作为分成比例. 然后将这个 position 的 tick range 中包含的所有 tick 的手续费相加, 就可以得到这一分钟的手续费收益.
关于【uniswap v3 数据清洗流程】的延伸阅读
长推:复盘精彩刺激的 $RCH 大战
昨晚,$RCH与BTW进行了精彩的大战,项目方上线了产品并给LP添加了700ETH,但被聪明钱抢跑。随后,神盘出现,币价从0.2上涨到1u。项目方背景强大,有大机构背书,链上交易活跃。Sofa.org推出了两个产品,Earn和Surge,用户可以利用期权策略进行理财和预测未来走势。产品实力强大,能力超过web3团队。
长推:$RCH 能不能到20亿?无预留、无权限、燃烧通缩、上所才是起点
$RCH是新兴项目,初始加入池子的ETH价值300万,现市值7000万。若跌回1块,市值为2000万,上限无法预测。项目方烧了750ETH,加其他支出,合计400万。预计市值达15M,产品和资方有潜力,交易量高,无VC抛压和项目方币。预计上市后,市值5亿-40亿。
用公式表示为:
 最后将 fee0 和 fee1 的手续费相加, 就得到了手续费净值. 再与流动性的净值相加, 就得到了总净值.
最后将 fee0 和 fee1 的手续费相加, 就得到了手续费净值. 再与流动性的净值相加, 就得到了总净值.
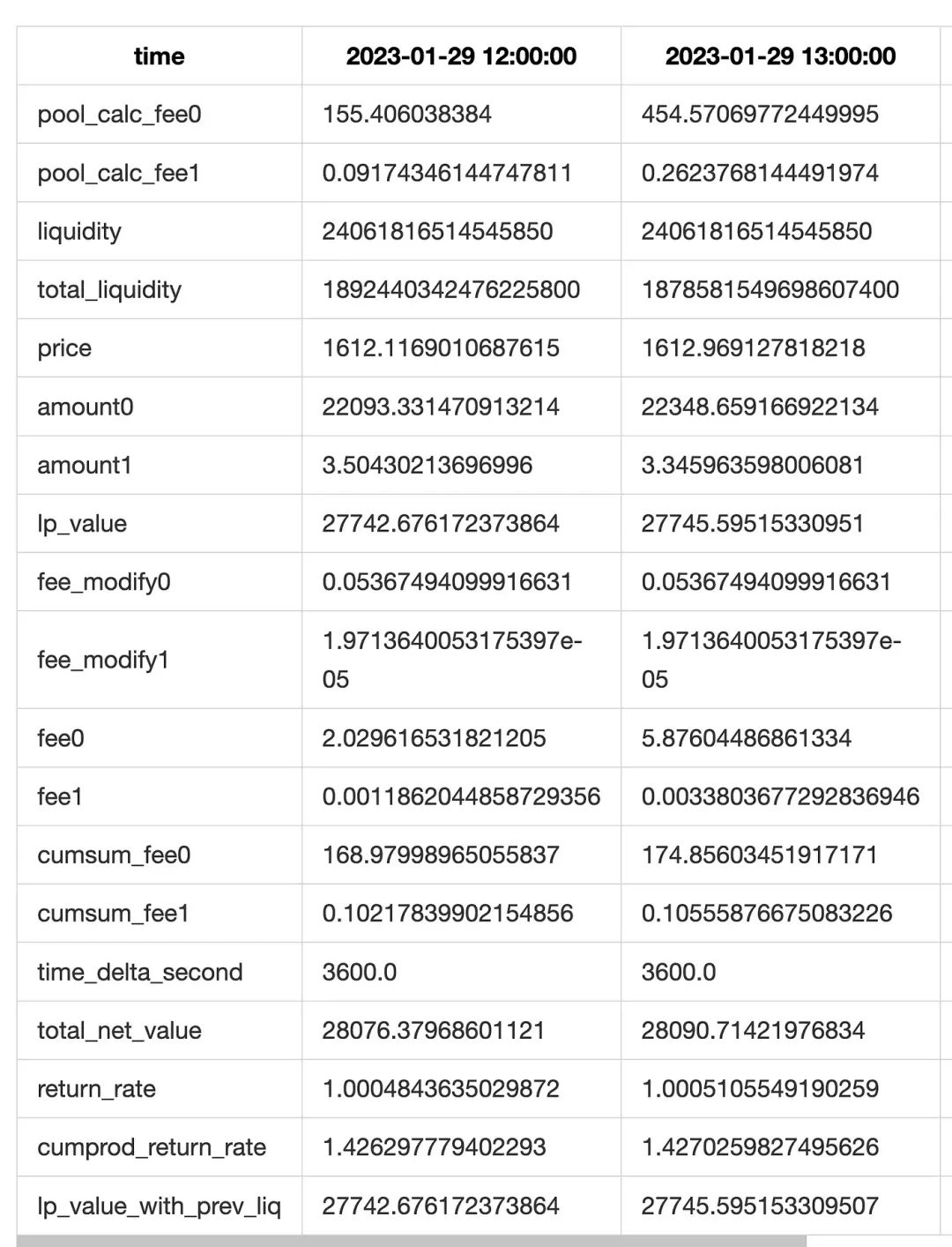
在计算净值时, 我们根据 mint/burn/collect 的交易分割 position 的生命周期.
- 当 mint 交易发生, 让流动性增加
- 当 burn 交易发生, 让流动性减少. 并将流动性的价值折算到手续费字段(pool 合约的代码也是这样操作的)
- 当 collect 交易发生. 会触发计算, 计算范围是从上次 collect 到当前时间, 我们会计算每分钟的净值和手续费收入, 得到一个列表.
最后, 将每次 collect 得到的净值列表汇总起来. 再进行 resample 和其它的统计. 得到最终的结果.
 另外为了提高精度, 我们做了两方面的优化.
另外为了提高精度, 我们做了两方面的优化.
首先, 对于有交易发生(mint/burn/collect)的那个小时, 我们进行分钟级的统计, 而对于没有交易发生的小时, 进行小时级的统计. 最后, 将结果 resample 成小时级.
其次, 在 collect event 中, 我们可以得到流动性+手续费的总和. 因此我们可以将实际 collect 的值, 与我们理论计算值对比, 得到理论手续费和实际手续费的差值(实际上这个差值还包含 lp 本金的差值, 但是 lp 本金的差值误差特别小, 基本可以认为是 0). 我们会将手续费差值补偿到每行上. 以提高手续费估算的精度(也就是上面的表中 fee_modify0 和 fee_modify1 字段).
注意:
- 回填的时候还要根据当前小时的流动性, 对手续费的分配进行加权, 否则会出现这个小时手续费偏高的情况.
- 由于统计的数据是 2023 年全年, 而不是完整数据, 因此存在第五节中提到的沉没流动性的现象. 这会让实际手续费比理论手续费多很多. 使得收益率变得异常高.
由于每一行是这个小时最后时刻的数据, 对于已经完全 close 的 position, 净值会是 0. 这种情况下, 这个 position close 时刻的净值就会丢失. 为了保留这个净值, 在文件末尾, 创建了一行时间为 2038-1-1 00:00:00 的数据, 存放 position close 时刻的净值等数据. 以备其他项目的统计需求.
收益率
通常, 计算收益率是用开始的净值, 除以结束的净值. 但是在这里并不适用. 原因如下:
- 这里的收益率需要细化到每一分钟,
- 由于 position 会在中途有资金的转入和转出. 单纯开始和结束的净值相除并不能体现收益情况.
对于问题 1, 我们可以用每一分钟的净值相除, 来得到每分钟的收益率, 然后将每分钟的收益率累乘, 就得到了总收益率.
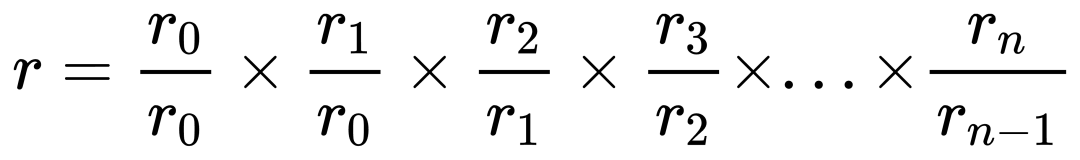 但这个算法有一个严重的问题. 如果每分钟收益率中, 有一个数据计算错误, 就会导致总收益率出现很大的偏差. 这样统计过程变成了走钢丝, 不能出现一点差错. 但好的方面是, 这让任何统计错误都无所遁形.
但这个算法有一个严重的问题. 如果每分钟收益率中, 有一个数据计算错误, 就会导致总收益率出现很大的偏差. 这样统计过程变成了走钢丝, 不能出现一点差错. 但好的方面是, 这让任何统计错误都无所遁形.
对于问题 2, 如果这分钟有资金的转入转出, 用收益率直接相除, 还是会得到很离谱的收益率.因此有必要细化一下每分钟的收益率算法.
我们采取的第一个尝试, 是将净值的变化进行详细的拆分, 然后将资金的变化剔除. 我们把净值的变化拆分为几个部分. 1 是价格带来的本金变化. 2 是这分钟的手续费累计. 3 是资金的流入流出. 显然 3 是要从统计中排除的. 对此我们制定了如下的计算方法:
- 指定当前分钟是 n, 前一分钟是 n-1
- 假定当前分钟的所有转帐操作, 都发生在第 n:0.000 秒. 那么在余下的时间, LP 的净值是不变的, 也就是说第 n:0.001 秒的净值等于 n:59.999 秒的净值.
- 手续费的累加发生在这一分钟的末尾.也就是第 n:59.999 秒.
- 上一分钟末尾(n-1:59.999)的价格和手续费, 就是这一分钟(n:0.000)开始的价格和手续费
基于以上假设, 每分钟的收益率就是用末尾的流动性/价格/手续费, 除以末尾的流动性/开始的价格/开始的手续费, 用公式表示如下, 其中 f 是指将 liquidity 折算为净值的算法.
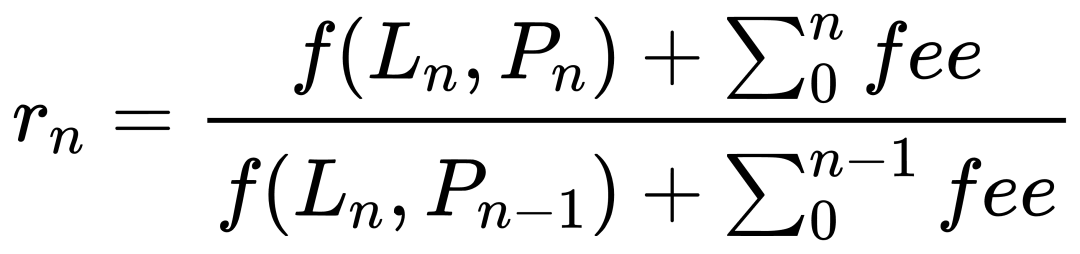 这种方式看起来很不错. 它完美的规避了流动性的变化. 并体现了价格和手续费对净值的影响. 这正是我们所期待的. 但是, 在实际当中, 会在某些行产生很大的收益率. 经过调查我们发现. 问题出现在撤出流动性的时候. 回忆一下我们的规则: 每行所代表的时间是这一分钟/小时的末尾. 这为数据的统计提供了统一的尺度, 但需要注意的是, 而每一列的含义是不一样的:
这种方式看起来很不错. 它完美的规避了流动性的变化. 并体现了价格和手续费对净值的影响. 这正是我们所期待的. 但是, 在实际当中, 会在某些行产生很大的收益率. 经过调查我们发现. 问题出现在撤出流动性的时候. 回忆一下我们的规则: 每行所代表的时间是这一分钟/小时的末尾. 这为数据的统计提供了统一的尺度, 但需要注意的是, 而每一列的含义是不一样的:
- 对于净值列来说是瞬时值, 也就是当前分钟/小时最后的值.
- 而手续费列是累加值. 也就是当前分钟/小时期间所累计的手续费
因此对于 burn 流动性的那个小时
- 当 LP 被 burn 掉, 然后 token 转移走的情况下, 在这个小时末尾净值会是 0
- 而对于手续费来说, 由于他是累加的, 在这个小时的末尾, 手续费会大于 0.
这就使得上面的公式退化为:
这种情况不仅仅会出现在 position 生命周期的末尾, 在 burn 一部分流动性的时候, 也会为让手续费的增加与 LP 的净值比例产生变化.
为了简化起见. 当发生 LP 的净值变化的时候, 我们设定收益率为 1. 这会为收益率的计算结果带来误差. 但是对于一个正常持续投资的 position 来说, 产生交易的小时相对于整个生命周期还是很少的. 因此影响并不大.
8. 计算地址的 LP 总收益
有了每个 position 的收益率, 再加上 position 和地址的对应关系, 就可以得到用户地址在每个 position 的收益率了.
这里的算法比较简单, 将这个地址在不同时期的 position 串联起来, 中间没有投资时期, 净值设置为 0, 收益率设置为 1(因为前后净值都是 0, 没有变化, 所以收益率是 1.)
如果同一个时期有多个 position. 则在重叠的部分, 将净值相加. 就可以得到总净值. 而合并收益率的时候, 我们会根据每个 position 的净值加权合并.
9. 合并现金和 LP 的总收益
最后, 只要将用户地址持有的现金和 LP 投资这两部分的综合起来, 就能得到最终结果了.
净值的合并相比于上个步骤(合并 position )更加简单. 只要在 LP 净值这边查到时间范围, 然后查找对应时间范围所持有的现金, 再查出 eth 的价格, 就可以得到总净值.
对于收益率, 我们同样采用求每分钟收益率, 然后累乘的算法. 一开始, 我们使用了第七节提到的错误收益率算法. 这要求将这一分钟的固定部分(包括现金中的 cash 数量, LP 中的流动性)和可变部分(价格变动, 手续费累计, 资金转入转出)分开. 相对与 position 的统计, 它的复杂度高出很多, 因为对于 uniswap 的资金流入流出, 只要关注 mint 和 collect 事件即可. 而对现金的追溯就非常麻烦, 我们要区分资金是转给 LP 还是转到外部. 如果是转给 LP, 本金部分可以不变, 如果是转到外部, 要修正本金的数量. 这就需要追踪 erc20 和 eth 的转帐目标地址. 这个工作非常麻烦. 首先在 mint/collect 时, 转帐地址可能是 pool, 也可能是 proxy. 而更复杂的是 eth 的转帐, 由于 eth 是 native token, 一些转帐记录只能通过 trace 记录查到. 但是 trace 的数据量太大, 超出了我们的处理能力.
最后压胯骆驼的最后一根稻草, 是我们发现每行的净值是这个小时的瞬时值, 手续费是这个小时的累计值, 从物理意义上不能直接相加. 这个问题确实很晚才发现.
因此我们放弃了这个算法. 转而采用后一分钟的净值, 除以前一分钟净值的方式. 这种方式简单很多. 但这种方式也存在一个问题. 那就是当有资金转入转出的时候, 收益率依然会出现不合理的情况. 通过上面的讨论, 我们得知拆分出资金的流向非常困难. 因此在这里我们牺牲一些精度, 将有资金转移时的收益率设置为1.
剩下的问题就是, 如何识别出当前小时有资金的流入流出? 一开始想的算法很简单, 用上一个小时的 token 余额, 以及当前的价格, 推算出如果持有这些 token, 那么这个小时净值会是多少. 然后将推算值, 与实际值相减就可以了. 当差值不等于的时候, 就是有资金转入转出. 用公式表示为:
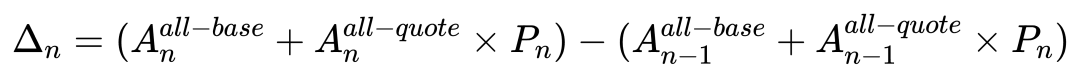 但是这个算法忽视了 uniswap LP 的复杂性. LP 中, token 的数量会随着价格的变动而变化,同时净值也会随之变化. 且这个方式没有考虑手续费的变化. 最终造成推测值与实际值有 0.1% 左右的误差.
但是这个算法忽视了 uniswap LP 的复杂性. LP 中, token 的数量会随着价格的变动而变化,同时净值也会随之变化. 且这个方式没有考虑手续费的变化. 最终造成推测值与实际值有 0.1% 左右的误差.
为了提高准确性, 将资金的构成细化一下, 把 lp 的价值变动单独计算, 同时把手续费也考虑进来.
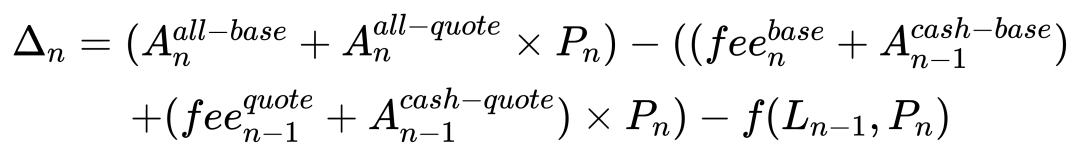 通过这种方式, 推测值的误差可以控制在 0.001% 以内.
通过这种方式, 推测值的误差可以控制在 0.001% 以内.
另外我们限制了数据的 decimal. 避免出现过小的数字(通常在 10^-10 以下)相除的情况. 这些小的数字, 是各种计算以及 resample 所累计出来的误差. 如果不处理直接相除, 会导致误差被放大. 使收益率严重失真.
其他的问题
native token
在本次统计加入了 ethereum 上的 usdc-eth 池, 其中 eth 是 native token , 需要进行一些特殊的处理.
eth 无法使用在 defi 中, 必须被转换为 weth. 因此这个 pool 实际上是 usdc-weth 的池子. 对于直接操作 pool 的用户来说, 在这个池转入转出 weth 即可. 这和普通的池子是一样的.
而对于通过 proxy 添加 LP 的用户来说, 需要将 eth 带在交易的 value 中, 转给 proxy 合约. 合约再将这些 eth 兑换成 weth, 然后再投入 pool 中. 而在 collect 的时候, usdc 可以直接转给用户, 而 eth 不能直接转给用户, 需要先从 pool 转出到 proxy, 再由 proxy 合约兑换成 eth, 最后通过内部转帐发送给用户. 例子见这个交易[4].
因此 usdc-eth pool 与普通 pool 只在资金的转入和转出有区别. 这只对匹配 position 和地址有影响. 为了解决这个问题, 我们拉取了池子从创立开始的所有 nft 转帐数据, 然后通过 token id 找到对应 position 的持有人.
missing position
在统计中, 有些 position 并没有进入到最后的列表. 这些 position 都有一定的特殊之处.
其中很大一部分是 mev 交易, mev 是纯套利的交易, 并不是正常的投资者, 因此不在我们的统计范围之列. 另外在实际统计中也很难对其进行统计, 这需要用到 trace 级别的数据. 在这里我们使用了一个简单的策略来过滤 mev 交易, 就是从开始到结束的时间不足一分钟, 事实上, 由于我们数据的最高精度是 1 分钟. 如果一个 position 的存在时间少于一分钟, 就无法被统计到.
另一种可能性是, 这个 position 没有 collect 交易. 从 step 7 可以看出, 我们对收益的计算, 是通过 collect 触发的. 没有 collect 操作, 就不会计算之前的净值和收益率. 在正常情况下, 用户都会选择及时收获 LP 的收益或者本金. 但也不排除一部分特殊用户, 就是要把资产存在 uniswap pool 的 fee0 和 fee1. 对于这种用户, 我们也认为是特殊用户, 不在统计范围内.
免责声明:本文仅代表作者个人观点,不代表链观CHAINLOOK立场,不承担法律责任。文章及观点也不构成投资意见。请用户理性看待市场风险,以及遵守所在国家和地区的相关法律法规。
图文来源:Zelos,如有侵权请联系删除。转载或引用请注明文章出处!
