从opBNB和以太坊Layer2的性能差异来理解Rollup的瓶颈与优化方式
本文旨在对opBNB的工作原理与其商业意义进行简要概括,为大家梳理BSC公链在模块化区块链时代迈出的重要一步。

原文作者:Faust
原文来源:极客web3
导语:如果用一个关键词来概括2023年的Web3,大多数人或许会本能想到“Layer2之夏”。虽然应用层创新此起彼伏,但能像L2一样经久不衰的长期热点却难得一见。随着Celestia成功推广模块化区块链概念,Layer2和模块化几乎成为了基础设施的代名词,单片链的往日辉煌似乎难以重现。在Coinbase、Bybit和Metamask相继推出专属的二层网络后,Layer2大战如火如荼,像极了当初新公链间炮火连天的场面。在这场由交易所引领的二层网络大战中,BNB Chain必然不肯甘居人下。早在去年他们就曾上线zkBNB测试网,但因为zkEVM在性能上还无法满足大规模应用,采用Optimistic Rollup方案的opBNB成为了实现通用Layer2的更优方案。本文旨在对opBNB的工作原理与其商业意义进行简要概括,为大家梳理BSC公链在模块化区块链时代迈出的重要一步。
BNB Chain的大区块之路
与Solana、Heco等由交易所扶持的公链类似,BNB Chain的公链BNB Smart Chain (BSC)链对高性能的追求由来已久。从2020年上线初,BSC链就把每个区块的gas容量上限设定在3000万,出块间隔稳定在3秒。
在这样的参数设置下,BSC实现了100+的TPS上限(各种交易杂糅在一起的TPS)。2021年6月,BSC的区块gas上限提升到了6000万,但在当年7月一款名为CryptoBlades的链游在BSC上爆火,引发的日交易笔数一度超过800万,导致手续费飙升。事实证明,此时的BSC效率瓶颈还是比较明显。
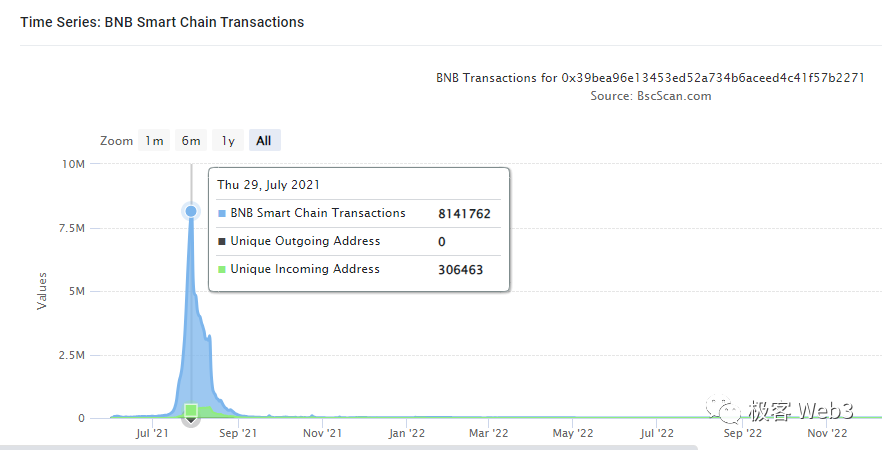 (数据来源:BscScan)
(数据来源:BscScan)
为了解决网络性能问题,BSC再次将每个区块的gas上限上调,此后长时间稳定在8000万~8500万附近。2022年9月,BSC Chain单个区块的gas上限提高到了1.2亿,年底时提高到了1.4亿,达到2020年时的近5倍。此前BSC曾计划把区块gas容量上限提升到3亿,或许是考虑到Validator节点的负担太重,上述超大区块的提议一直没有实施。
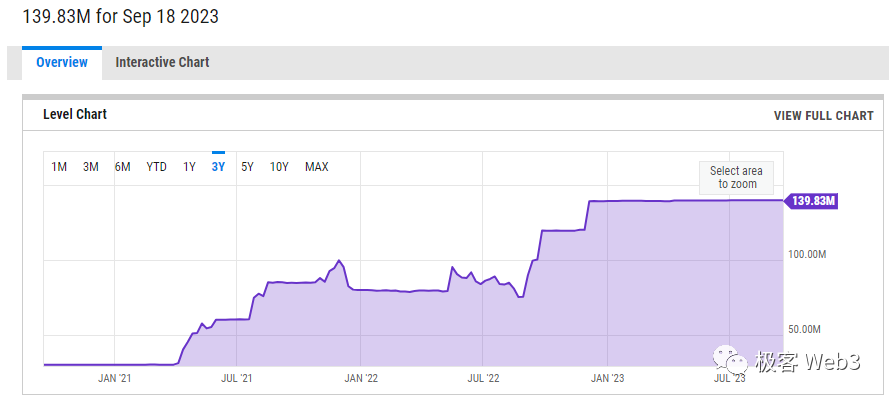 (数据来源:YCHARTS)
(数据来源:YCHARTS)
后来的BNB Chain似乎将重心放在了模块化/Layer2赛道,而没有再执着于Layer1的扩容。从去年下半年上线的zkBNB到今年年初时的GreenField,这一意图表现的愈加明显。出于对模块化区块链/Layer2的浓厚兴趣,本文作者将以opBNB为调研对象,从opBNB与以太坊Layer2表现出的不同,来为读者简单揭示Rollup的性能瓶颈所在。
BSC的高吞吐量对opBNB的DA层加成
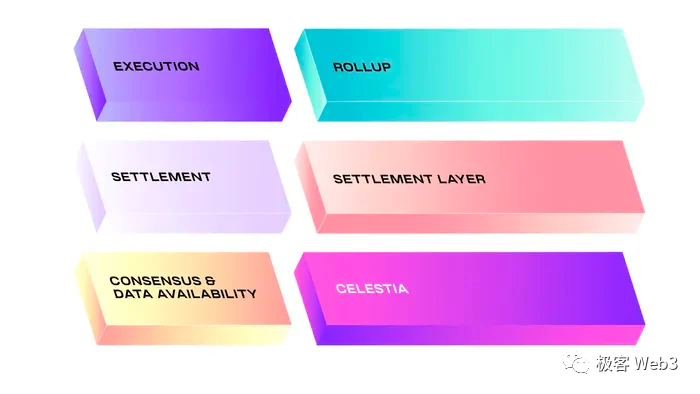
众所周知,Celestia按照模块化区块链的工作流程,归纳出了4个关键组件:
执行层Execution:执行合约代码、完成状态转换的执行环境;
结算层Settlement:处理欺诈证明/有效性证明,同时处理L2与L1之间的桥接问题。
共识层Consensus:对交易的排序达成一致共识。
数据可用性层Data availability (DA):发布区块链账本相关数据,使得验证者可以下载到这些数据。
 其中,DA层与共识层往往被耦合在一起。比如,乐观Rollup的DA数据包含了一批L2区块中的交易序列,当L2全节点获取到DA数据时,其实就知道了这批交易中每笔Tx的先后次序。(正因如此,以太坊社区对Rollup分层时,认为DA层和共识层是关联的)
其中,DA层与共识层往往被耦合在一起。比如,乐观Rollup的DA数据包含了一批L2区块中的交易序列,当L2全节点获取到DA数据时,其实就知道了这批交易中每笔Tx的先后次序。(正因如此,以太坊社区对Rollup分层时,认为DA层和共识层是关联的)
 但对于以太坊Layer2而言,DA层(以太坊)的数据吞吐量成为了制约Rollup性能的最大瓶颈,因为目前以太坊的数据吞吐量太低,Rollup不得不尽量压制自己的TPS,防止以太坊主网无法承载L2产生的数据。同时,低下的数据吞吐量使得Ethereum网络内大量交易指令处于待处理状态,这使得gas费被拉到了极高水准,进一步抬高了Layer2的数据发布成本。最后,很多二层网络不得不采用Celestia等以太坊之外的DA层,“近水楼台先得月”的opBNB则直接选用高吞吐量的BSC实现DA,以解决数据发布上的瓶颈问题。为了方便理解,此处需要介绍一下Rollup的DA数据发布方式。以Arbitrum为例,Layer2排序器控制的以太坊链上EOA地址,会定期往指定的合约发出Transaction,在这个指令的输入参数calldata中,写入打包好的交易数据,并触发相应的链上事件,在合约日志中留下永久记录。
但对于以太坊Layer2而言,DA层(以太坊)的数据吞吐量成为了制约Rollup性能的最大瓶颈,因为目前以太坊的数据吞吐量太低,Rollup不得不尽量压制自己的TPS,防止以太坊主网无法承载L2产生的数据。同时,低下的数据吞吐量使得Ethereum网络内大量交易指令处于待处理状态,这使得gas费被拉到了极高水准,进一步抬高了Layer2的数据发布成本。最后,很多二层网络不得不采用Celestia等以太坊之外的DA层,“近水楼台先得月”的opBNB则直接选用高吞吐量的BSC实现DA,以解决数据发布上的瓶颈问题。为了方便理解,此处需要介绍一下Rollup的DA数据发布方式。以Arbitrum为例,Layer2排序器控制的以太坊链上EOA地址,会定期往指定的合约发出Transaction,在这个指令的输入参数calldata中,写入打包好的交易数据,并触发相应的链上事件,在合约日志中留下永久记录。
 这样一来,Layer2的交易数据被长期保存在了以太坊区块中,有能力运行L2节点的人可以下载相应的记录,解析出对应数据,但以太坊自己的节点并不执行这些L2交易。不难看出,L2只是把交易数据存放到以太坊区块中,产生了存储成本,而执行交易的计算成本被L2自己的节点承担了。上面讲到的就是Arbitrum的DA实现方式,而Optimism则是由排序器控制的EOA地址,向另一个指定的EOA地址进行Transfer,在附加的数据中携带Layer2的新一批交易数据。至于采用了OP Stack的opBNB,和Optimism的DA数据发布方式基本一致。
这样一来,Layer2的交易数据被长期保存在了以太坊区块中,有能力运行L2节点的人可以下载相应的记录,解析出对应数据,但以太坊自己的节点并不执行这些L2交易。不难看出,L2只是把交易数据存放到以太坊区块中,产生了存储成本,而执行交易的计算成本被L2自己的节点承担了。上面讲到的就是Arbitrum的DA实现方式,而Optimism则是由排序器控制的EOA地址,向另一个指定的EOA地址进行Transfer,在附加的数据中携带Layer2的新一批交易数据。至于采用了OP Stack的opBNB,和Optimism的DA数据发布方式基本一致。
关于【从opBNB和以太坊Layer2的性能差异来理解Rollup的瓶颈与优化方式】的延伸阅读
探索 Sui 生态:DEX 交易量环比增长 4 倍,游戏应用正在崛起
Sui是一个基于权益证明的区块链,代币总供应量为100亿,具有创新功能。其生态系统获得了显著的采用,TVL环比增长了240%,DEX交易量环比增长了407%。Sui基金会正在投资社区建设活动,如Sui Overflow和Sui Basecamp。Sui应用活动可以帮助投资者分析实时趋势和用户活动。Sui网络的交易量和DeFi使用量都呈现出大幅增长,其中包括通过Telegram钱包玩游戏来挖掘OCEAN的交易。Sui的生态系统发展方向包括DeFi、游戏和社交领域。Sui基金会加强社区建设,使用Artemis的Sui Application Activity可以监控和分析实时链活动。
速读 Coinbase 智能钱包:有何亮点?如何与 Coinbase 交易所打通?
Coinbase推出智能钱包,简化登录、无Gas体验、支持用余额支付,吸引交易所上亿用户,实现全新链上体验。智能钱包创建简单,可使用多种方式备份,保证资金安全。支持自托管钱包或Coinbase账户余额支付,提供无Gas费用的交易体验,易于开发者集成。已有数千个DApp集成,包括DeFi、社区、游戏和社交项目,为用户打开通往无限可能的链上世界的大门。Base还推出Onchain Summer活动,提供总共600 ETH奖励,开发者集成智能钱包有机会获得额外的40 ETH奖励。Coinbase智能钱包有望吸引大量用户,为Base链带来更多关注。
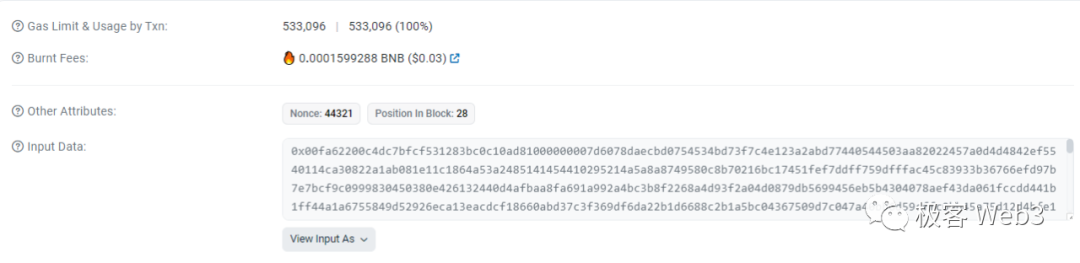
 显而易见,DA层的吞吐量会对单位时间内Rollup可发布的数据尺寸大小产生限制,进而限制TPS。考虑到EIP1559后,每个ETH区块的gas容量稳在3000万,merge后出块时间约为12秒,则以太坊每秒处理的gas总量最多仅250万。绝大多数时候,容纳L2交易数据的calldata,每个字节消耗的gas = 16,则以太坊每秒能处理的calldata尺寸最多只有150 KB。而BSC平均每秒可处理的calldata尺寸最大约2910 KB,达到了以太坊的18.6倍。两者作为DA层的差距是显而易见的。可以概括一下,以太坊每秒最多可承载150 KB左右的L2交易数据。即便在EIP 4844上线后,这个数字也不会有多大改变,只不过降低了DA手续费。那么每秒150KB,大概能包含多少笔交易的数据?这里需要解释下Rollup的数据压缩率。Vitalik在2021年曾过分乐观的估计,乐观Rollup可以把交易数据尺寸,压缩至原先的11%。比如,一笔最基础的ETH转账,原本占用calldata大小是112字节,可以被乐观Rollup压缩到12字节,ERC-20转账可以压缩到16字节,Uniswap上的Swap交易压缩到14字节。按照他的说法,以太坊每秒最多能记录1万笔左右的L2交易数据(各类型掺杂在一起)。但按照Optimism官方在2022年披露的数据,实践中的数据压缩率,最高只能达到约37%,与Vitalik的估算差了3.5倍。
显而易见,DA层的吞吐量会对单位时间内Rollup可发布的数据尺寸大小产生限制,进而限制TPS。考虑到EIP1559后,每个ETH区块的gas容量稳在3000万,merge后出块时间约为12秒,则以太坊每秒处理的gas总量最多仅250万。绝大多数时候,容纳L2交易数据的calldata,每个字节消耗的gas = 16,则以太坊每秒能处理的calldata尺寸最多只有150 KB。而BSC平均每秒可处理的calldata尺寸最大约2910 KB,达到了以太坊的18.6倍。两者作为DA层的差距是显而易见的。可以概括一下,以太坊每秒最多可承载150 KB左右的L2交易数据。即便在EIP 4844上线后,这个数字也不会有多大改变,只不过降低了DA手续费。那么每秒150KB,大概能包含多少笔交易的数据?这里需要解释下Rollup的数据压缩率。Vitalik在2021年曾过分乐观的估计,乐观Rollup可以把交易数据尺寸,压缩至原先的11%。比如,一笔最基础的ETH转账,原本占用calldata大小是112字节,可以被乐观Rollup压缩到12字节,ERC-20转账可以压缩到16字节,Uniswap上的Swap交易压缩到14字节。按照他的说法,以太坊每秒最多能记录1万笔左右的L2交易数据(各类型掺杂在一起)。但按照Optimism官方在2022年披露的数据,实践中的数据压缩率,最高只能达到约37%,与Vitalik的估算差了3.5倍。
 (Vitalik对Rollup扩容效应的估算,很大程度偏离了实际情况)
(Vitalik对Rollup扩容效应的估算,很大程度偏离了实际情况)
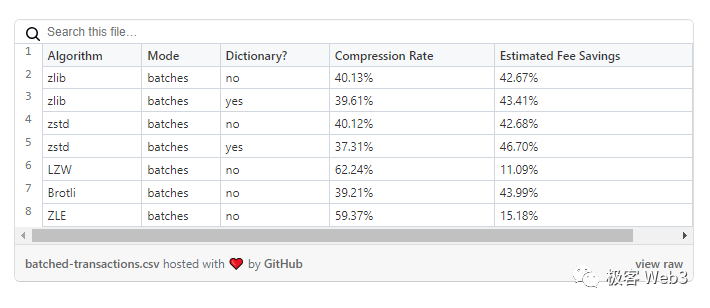 (Optimism官方公布的各种压缩算法实际取得的压缩率)所以我们不妨给出一个合理的数字,就是目前以太坊即便达到自己的吞吐量极限,所有乐观Rollup加起来的TPS最大值,也只有2000多。换句话说,如果以太坊区块全部空间都用来承载乐观Rollup发布的数据,比如被Arbitrum、Optimism、Base、Boba等瓜分,这些乐观Rollup的TPS加起来根本不够3000,这还是在压缩算法效率最高的情况下。此外,我们还要考虑到EIP1559后,每个区块平均承载的gas量仅为最大值的50%,所以上面的数字还应该砍掉一半。EIP4844上线后,尽管会把发布数据的手续费大幅降低,但以太坊的区块最大尺寸不会有多大变化(变化太多会影响ETH主链的安全性),所以上面估算的数值不会有多少进步。
(Optimism官方公布的各种压缩算法实际取得的压缩率)所以我们不妨给出一个合理的数字,就是目前以太坊即便达到自己的吞吐量极限,所有乐观Rollup加起来的TPS最大值,也只有2000多。换句话说,如果以太坊区块全部空间都用来承载乐观Rollup发布的数据,比如被Arbitrum、Optimism、Base、Boba等瓜分,这些乐观Rollup的TPS加起来根本不够3000,这还是在压缩算法效率最高的情况下。此外,我们还要考虑到EIP1559后,每个区块平均承载的gas量仅为最大值的50%,所以上面的数字还应该砍掉一半。EIP4844上线后,尽管会把发布数据的手续费大幅降低,但以太坊的区块最大尺寸不会有多大变化(变化太多会影响ETH主链的安全性),所以上面估算的数值不会有多少进步。
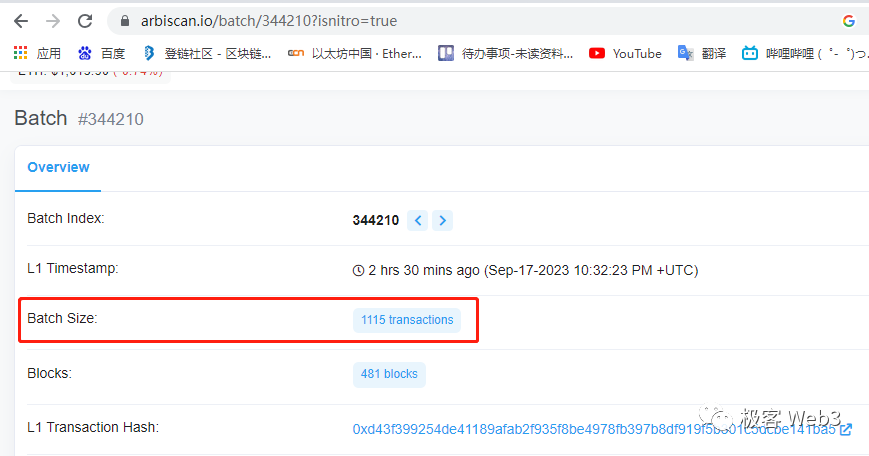
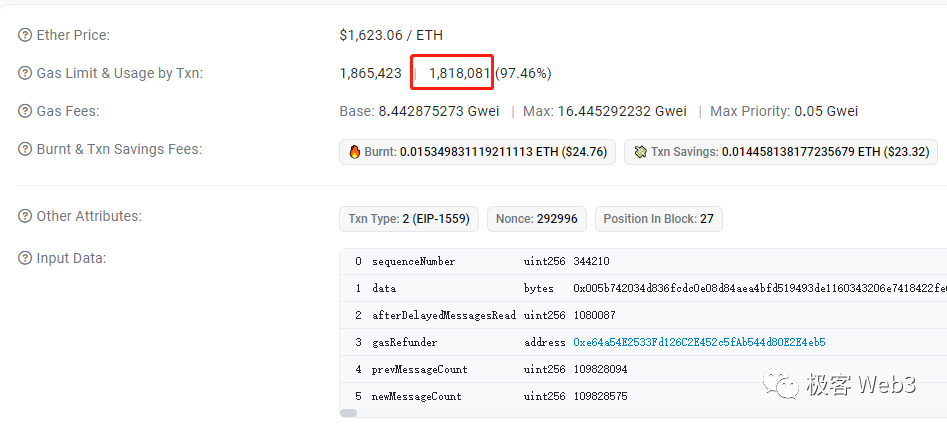 根据Arbiscan和Etherscan的数据,Arbitrum某个交易批次包含了1115笔交易,在以太坊上消耗了181万的gas。如此推算,如果把DA层每个区块都装满,Arbitrum理论上的TPS极限约为1500,当然考虑到L1区块重组问题,Arbitrum不可能在每个以太坊区块上都发布交易批次,所以上面的数字目前只是纸面上的。同时,在EIP 4337相关的智能钱包被大规模采用后,DA问题会愈加严重。因为支持EIP 4337后,用户验证身份的方式可以自定义,比如上传指纹或虹膜的二进制数据,这会进一步加大常规交易占用的数据尺寸。所以,以太坊低下的数据吞吐量是限制Rollup效率的最大瓶颈,这个问题今后很长时间可能都无法妥善解决。而在BNB chain的公链BSC身上,平均每秒可处理的calldata尺寸最大约2910 KB,达到了以太坊的18.6倍。换言之,只要执行层速度跟的上,BNB Chain体系内的Layer2,理论TPS上限可以达到ARB或OP的18倍左右。这个数字是以当前BNB chain每个区块gas容量最大1.4亿,出块时间为3秒,计算得来的。
根据Arbiscan和Etherscan的数据,Arbitrum某个交易批次包含了1115笔交易,在以太坊上消耗了181万的gas。如此推算,如果把DA层每个区块都装满,Arbitrum理论上的TPS极限约为1500,当然考虑到L1区块重组问题,Arbitrum不可能在每个以太坊区块上都发布交易批次,所以上面的数字目前只是纸面上的。同时,在EIP 4337相关的智能钱包被大规模采用后,DA问题会愈加严重。因为支持EIP 4337后,用户验证身份的方式可以自定义,比如上传指纹或虹膜的二进制数据,这会进一步加大常规交易占用的数据尺寸。所以,以太坊低下的数据吞吐量是限制Rollup效率的最大瓶颈,这个问题今后很长时间可能都无法妥善解决。而在BNB chain的公链BSC身上,平均每秒可处理的calldata尺寸最大约2910 KB,达到了以太坊的18.6倍。换言之,只要执行层速度跟的上,BNB Chain体系内的Layer2,理论TPS上限可以达到ARB或OP的18倍左右。这个数字是以当前BNB chain每个区块gas容量最大1.4亿,出块时间为3秒,计算得来的。
 也就是说,目前BNB Chain体系下的公链,所有Rollup加总TPS极限,是以太坊的18.6倍(就算考虑进ZKRollup,也是如此)。从这一点也可以理解,为什么那么多Layer2项目用以太坊链下的DA层来发布数据,因为差异是显而易见的。但是,问题没有这么简单。除了数据吞吐量问题外,Layer1本身的稳定性也会对Layer2造成影响。比如大多数Rollup往往要间隔几分钟才往以太坊上发布一次交易批次,这是考虑到Layer1区块有重组的可能性。如果L1区块重组,会波及到L2的区块链账本。所以,排序器每发布一个L2交易批次后,会再等多个L1新区块发布完,区块回滚概率大幅下降后,才发布下一个L2交易批次。这其实会推迟L2区块被最终确认的时间,降低大宗交易的确认速度(大额交易要结果不可逆转,才能保障安全)。简要概括,L2发生的交易只有发布到DA层区块内,且DA层又新产生了一定量的区块后,才具备不可逆转性,这是限制Rollup性能的一个重要原因。但以太坊出块速度慢,12秒才出一个块,假设Rollup每隔15个区块发布一个L2批次,不同批次间会有3分钟的间隔,而且每个批次发布后,还要等待多个L1区块产生,才会不可逆转(前提是不会被挑战)。显然以太坊L2上的交易从发起到不可逆转,等待时间很长,结算速度慢;而BNB Chain只需3秒就可以出一个块,区块不可逆转只需要45秒(产生15个新区块的时间)。根据目前的参数,在L2交易数量相同且考虑到L1区块不可逆转性的前提下,单位时间内opBNB发布交易数据的次数,最多可以达到Arbitrum的8.53倍(前者45s发一次,后者6.4min发一次),显然opBNB上大额交易的结算速度,要比以太坊L2快很多。同时,opBNB每次发布的最大数据量,可以达到以太坊L2的4.66倍(前者L1区块的gas上限1.4亿,后者是3000万)。8.53*4.66=39.74,这就是opBNB目前实践中,与Arbitrum在TPS极限上的差距(目前ARB为了安全,貌似主动压低了TPS,但理论上如果要调高TPS,还是和opBNB很多倍)
也就是说,目前BNB Chain体系下的公链,所有Rollup加总TPS极限,是以太坊的18.6倍(就算考虑进ZKRollup,也是如此)。从这一点也可以理解,为什么那么多Layer2项目用以太坊链下的DA层来发布数据,因为差异是显而易见的。但是,问题没有这么简单。除了数据吞吐量问题外,Layer1本身的稳定性也会对Layer2造成影响。比如大多数Rollup往往要间隔几分钟才往以太坊上发布一次交易批次,这是考虑到Layer1区块有重组的可能性。如果L1区块重组,会波及到L2的区块链账本。所以,排序器每发布一个L2交易批次后,会再等多个L1新区块发布完,区块回滚概率大幅下降后,才发布下一个L2交易批次。这其实会推迟L2区块被最终确认的时间,降低大宗交易的确认速度(大额交易要结果不可逆转,才能保障安全)。简要概括,L2发生的交易只有发布到DA层区块内,且DA层又新产生了一定量的区块后,才具备不可逆转性,这是限制Rollup性能的一个重要原因。但以太坊出块速度慢,12秒才出一个块,假设Rollup每隔15个区块发布一个L2批次,不同批次间会有3分钟的间隔,而且每个批次发布后,还要等待多个L1区块产生,才会不可逆转(前提是不会被挑战)。显然以太坊L2上的交易从发起到不可逆转,等待时间很长,结算速度慢;而BNB Chain只需3秒就可以出一个块,区块不可逆转只需要45秒(产生15个新区块的时间)。根据目前的参数,在L2交易数量相同且考虑到L1区块不可逆转性的前提下,单位时间内opBNB发布交易数据的次数,最多可以达到Arbitrum的8.53倍(前者45s发一次,后者6.4min发一次),显然opBNB上大额交易的结算速度,要比以太坊L2快很多。同时,opBNB每次发布的最大数据量,可以达到以太坊L2的4.66倍(前者L1区块的gas上限1.4亿,后者是3000万)。8.53*4.66=39.74,这就是opBNB目前实践中,与Arbitrum在TPS极限上的差距(目前ARB为了安全,貌似主动压低了TPS,但理论上如果要调高TPS,还是和opBNB很多倍)
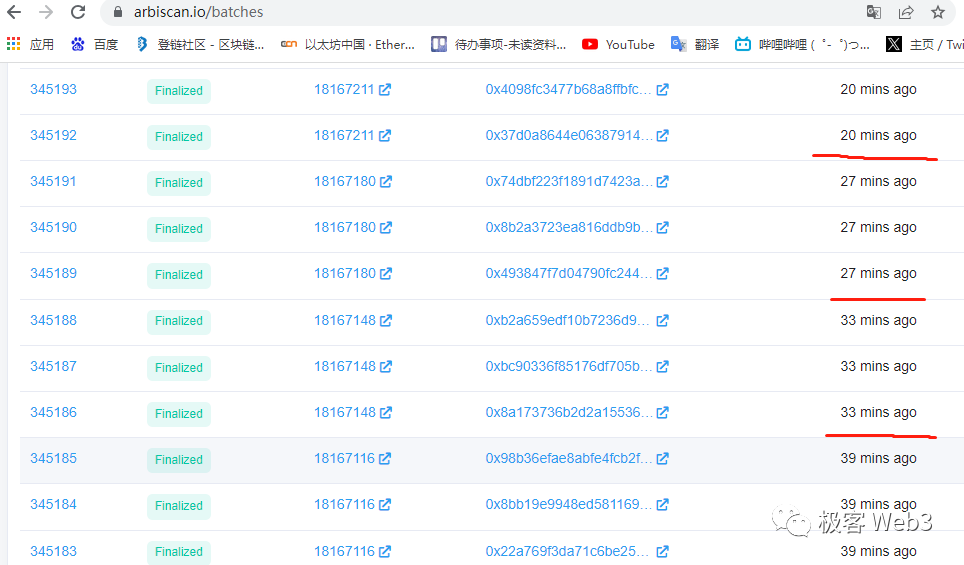 (Arbitrum的排序器每隔6~7分钟发布一次交易批次)
(Arbitrum的排序器每隔6~7分钟发布一次交易批次)
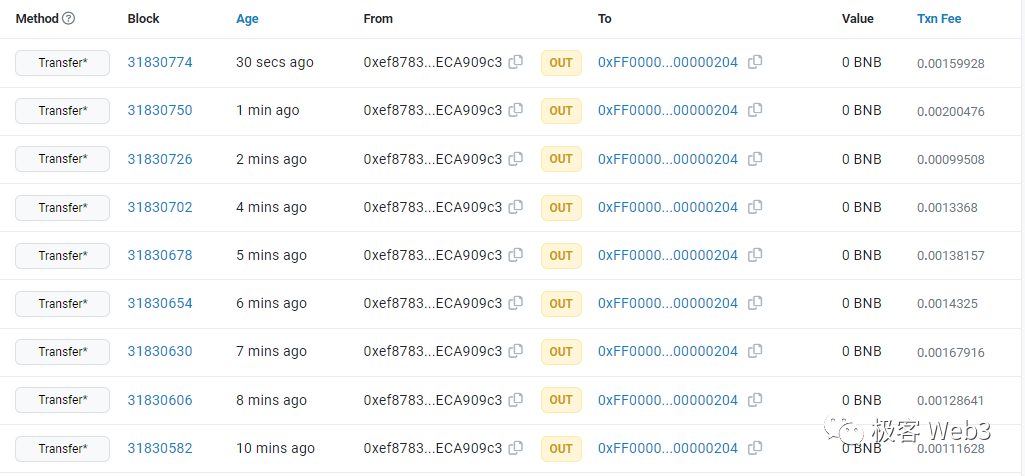
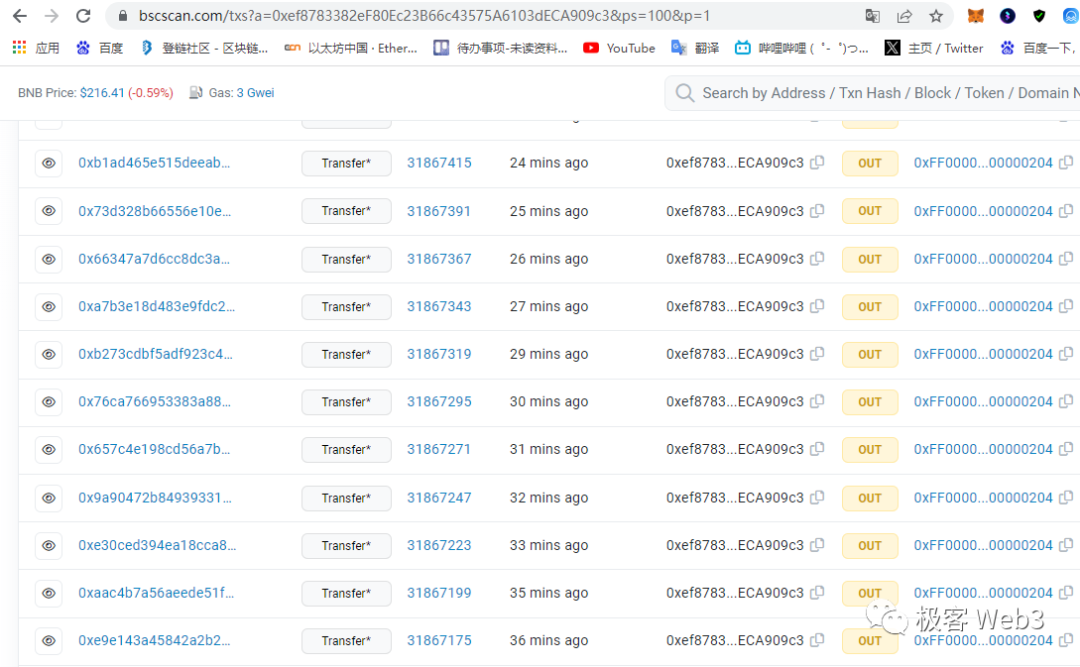 (opBNB的排序器每隔1~2分钟就会发布一次交易批次,最快只需要45秒)当然还有更重要的问题需要考虑,就是DA层的gas费。L2每发布一个交易批次,都有与calldata尺寸无关的固定成本——21000的gas,这也是一笔开销。如果DA层/L1手续费很高,使得L2每次发布交易批次的固定成本居高不下,排序器就会降低发布交易批次的频率。同时,在考虑L2手续费成分时,执行层的成本很低,大多数时候可以把它忽略,只考虑DA成本对手续费的影响。总结下来,在以太坊和BNB Chain上发布同样尺寸的calldata数据,虽然消耗的gas相同,但以太坊收取的gas price约是BNB chain的10—几十倍,传导到L2手续费上,目前以太坊Layer2的用户手续费大概也是opBNB的10—几十倍左右。综合下来,opBNB与以太坊上的乐观Rollup,差别还是很明显的。
(opBNB的排序器每隔1~2分钟就会发布一次交易批次,最快只需要45秒)当然还有更重要的问题需要考虑,就是DA层的gas费。L2每发布一个交易批次,都有与calldata尺寸无关的固定成本——21000的gas,这也是一笔开销。如果DA层/L1手续费很高,使得L2每次发布交易批次的固定成本居高不下,排序器就会降低发布交易批次的频率。同时,在考虑L2手续费成分时,执行层的成本很低,大多数时候可以把它忽略,只考虑DA成本对手续费的影响。总结下来,在以太坊和BNB Chain上发布同样尺寸的calldata数据,虽然消耗的gas相同,但以太坊收取的gas price约是BNB chain的10—几十倍,传导到L2手续费上,目前以太坊Layer2的用户手续费大概也是opBNB的10—几十倍左右。综合下来,opBNB与以太坊上的乐观Rollup,差别还是很明显的。
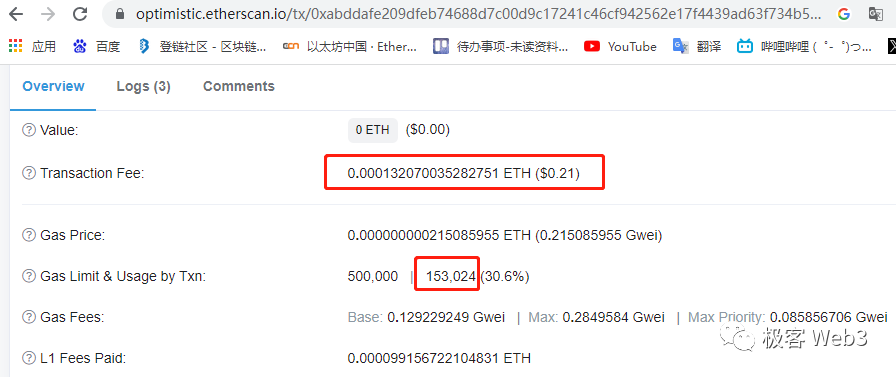 (Optimism上一笔消耗15万gas的交易,手续费0.21美元)
(Optimism上一笔消耗15万gas的交易,手续费0.21美元)
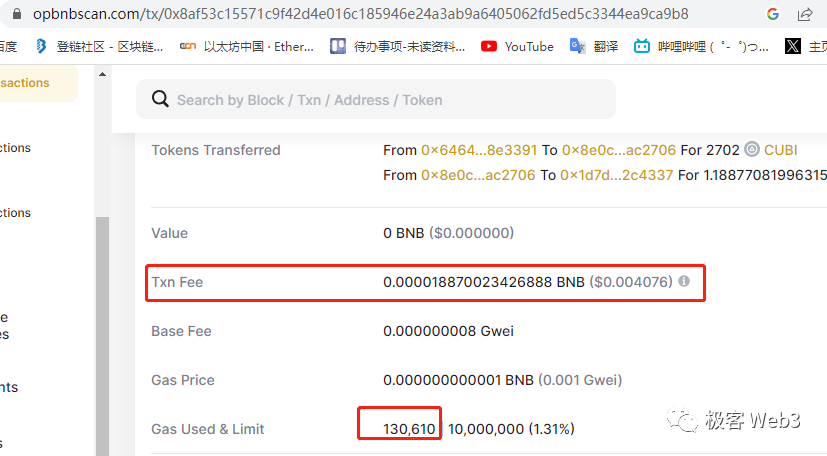 (opBNB上一笔消耗13万gas的交易,手续费0.004美元)但是,扩大DA层的数据吞吐量,虽然可以提升整个Layer2体系的吞吐量,但对单个Rollup的性能提升还是有限,因为执行层处理交易的速度往往不够快,即便DA层的限制可以忽略掉,执行层也会成为影响Rollup性能的下一个瓶颈。如果Layer2执行层的速度很慢,溢出的交易需求就会蔓延到其他Layer2上,最终造成流动性的割裂。所以,提升执行层的性能也很重要,是DA层之上的又一道门槛。
(opBNB上一笔消耗13万gas的交易,手续费0.004美元)但是,扩大DA层的数据吞吐量,虽然可以提升整个Layer2体系的吞吐量,但对单个Rollup的性能提升还是有限,因为执行层处理交易的速度往往不够快,即便DA层的限制可以忽略掉,执行层也会成为影响Rollup性能的下一个瓶颈。如果Layer2执行层的速度很慢,溢出的交易需求就会蔓延到其他Layer2上,最终造成流动性的割裂。所以,提升执行层的性能也很重要,是DA层之上的又一道门槛。
opBNB在执行层的加成:缓存优化当大多数人谈到区块链执行层的性能瓶颈时,必然会提到:EVM的单线程串行执行方式无法充分利用CPU、以太坊采用的Merkle Patricia Trie查找数据效率太低,这是两个重要的执行层瓶颈所在。说白了,对执行层的扩容思路,无非是更充分的利用CPU资源,再就是让CPU尽可能快的获取到数据。针对EVM串行执行和Merkle Patricia Tree的优化方案往往比较复杂,并不是很好实现,而投入性价比更高的工作常聚集在对缓存的优化上。其实缓存优化问题,回到了传统Web2乃至教科书中经常讨论到的点。通常情况下,CPU从内存读取数据的速度,是从磁盘读取数据速度的上百倍,比如一段数据,CPU从内存中读取只需要0.1秒,从磁盘中读取则需要10秒。所以,降低在磁盘读写上产生的开销,也即缓存优化,成为了区块链执行层优化中必需的一环。在以太坊乃至绝大多数公链中,记录链上地址状态的数据库被完整存储在磁盘当中,而所谓的世界状态World State trie只是这个数据库的索引,或者说查找数据时用到的目录。EVM每次执行合约都需要获取相关的地址状态,如果数据都要从存放在磁盘里的数据库中一条条拿过来,显然会严重降低执行交易的速度。所以在数据库/磁盘之外设置缓存,是必要的提速手段。opBNB直接采用了BNB Chain用到的缓存优化方案。按照opBNB的合作方NodeReal披露的信息,最早的BSC链在EVM与存放状态的LevelDB数据库之间设置了3道缓存,设计思路类似于传统的三级缓存,把访问频率更高的数据放到缓存中,这样CPU就可以先去缓存中寻找需要的数据。如果缓存的命中率足够高,CPU就不需要过分依赖磁盘来获取数据,整个执行过程的速度就可以实现大幅提升。

后来NodeReal在此之上增设了一个功能,调动EVM没占用的空闲CPU核心,把EVM未来要处理的数据,提前从数据库中读出来,放入缓存中,让EVM未来能从缓存直接获得需要的数据,这个功能被称为“状态预读”。
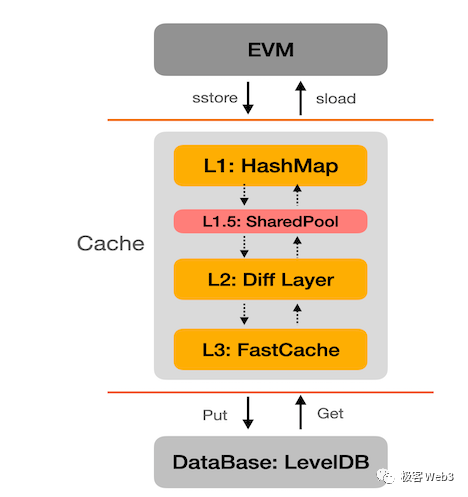 状态预读的道理其实很简单:区块链节点的CPU是多核心的,而EVM是单线程的串行执行模式,只用到1个CPU核心,这样其他的CPU核心就没有被充分利用。对此,可以让EVM没用到的CPU核心帮忙做点事,它们可以从EVM未处理的交易序列中,获知未来EVM会用到的数据都有哪些。然后,这些EVM之外的CPU核心,会从数据库中读取EVM未来会用到的数据,帮EVM解决数据获取上的开销,提升执行速度。在对缓存进行了充分优化后,搭配上性能足够的硬件配置,opBNB其实已经把节点执行层的性能逼近到了EVM的极限:每秒最多能处理1亿gas。1亿gas基本就是无改动的EVM的性能天花板(来自于某明星公链的实验测试数据)。具体概括的话,opBNB每秒最多可处理4761笔最简单的转账,处理1500~3000笔ERC20转账,处理约500~1000笔SWAP操作(这些数据根据区块浏览器上的交易数据获知)。以目前的参数对比看的话,opBNB的TPS极限,是以太坊的40倍,BNB Chain的2倍多,Optimism的6倍多。当然,以太坊Layer2因为DA层本身的严重限制,执行层根本施展不开,如果把此前曾提到的DA层出块时间、稳定性等因素都考虑进去,以太坊Layer2的实际性能要在执行层性能基础上大打折扣。而对于BNB Chain这样的高吞吐量DA层而言,扩容效应达到2倍多的opBNB是很有价值的,更何况这样的扩容项目BNB Chain可以搭载多个。可以预见的是,BNB Chain已经把opBNB为首的Layer2方案列入自己的布局计划中,未来还会不断收纳更多的模块化区块链项目,包括在opBNB里引入ZK proof,并搭配GreenField等配套基础设施来提供高可用的DA层,尝试与以太坊Layer2体系竞争亦或合作。在这个分层扩容已成为大势所趋的时代背景下,其他公链是否也会争相模仿BNB Chain扶持自己的Layer2项目,一切都有待时间去验证,但毫无疑问的是,以模块化区块链为大方向得到基础设施范式革命正在且已经发生了。
状态预读的道理其实很简单:区块链节点的CPU是多核心的,而EVM是单线程的串行执行模式,只用到1个CPU核心,这样其他的CPU核心就没有被充分利用。对此,可以让EVM没用到的CPU核心帮忙做点事,它们可以从EVM未处理的交易序列中,获知未来EVM会用到的数据都有哪些。然后,这些EVM之外的CPU核心,会从数据库中读取EVM未来会用到的数据,帮EVM解决数据获取上的开销,提升执行速度。在对缓存进行了充分优化后,搭配上性能足够的硬件配置,opBNB其实已经把节点执行层的性能逼近到了EVM的极限:每秒最多能处理1亿gas。1亿gas基本就是无改动的EVM的性能天花板(来自于某明星公链的实验测试数据)。具体概括的话,opBNB每秒最多可处理4761笔最简单的转账,处理1500~3000笔ERC20转账,处理约500~1000笔SWAP操作(这些数据根据区块浏览器上的交易数据获知)。以目前的参数对比看的话,opBNB的TPS极限,是以太坊的40倍,BNB Chain的2倍多,Optimism的6倍多。当然,以太坊Layer2因为DA层本身的严重限制,执行层根本施展不开,如果把此前曾提到的DA层出块时间、稳定性等因素都考虑进去,以太坊Layer2的实际性能要在执行层性能基础上大打折扣。而对于BNB Chain这样的高吞吐量DA层而言,扩容效应达到2倍多的opBNB是很有价值的,更何况这样的扩容项目BNB Chain可以搭载多个。可以预见的是,BNB Chain已经把opBNB为首的Layer2方案列入自己的布局计划中,未来还会不断收纳更多的模块化区块链项目,包括在opBNB里引入ZK proof,并搭配GreenField等配套基础设施来提供高可用的DA层,尝试与以太坊Layer2体系竞争亦或合作。在这个分层扩容已成为大势所趋的时代背景下,其他公链是否也会争相模仿BNB Chain扶持自己的Layer2项目,一切都有待时间去验证,但毫无疑问的是,以模块化区块链为大方向得到基础设施范式革命正在且已经发生了。
免责声明:本文仅代表作者个人观点,不代表链观CHAINLOOK立场,不承担法律责任。文章及观点也不构成投资意见。请用户理性看待市场风险,以及遵守所在国家和地区的相关法律法规。
图文来源:Faust,如有侵权请联系删除。转载或引用请注明文章出处!
