史上最全ChatGPT说明书
虽然in-context learning 被证明具有一定的有效性,但是其结果相比fine-tuing 还有一定的距离。

原文作者:许明
原文来源:github.io
原文标题:From zero to ChatGPT
Language Model
长期一来,人类一直梦想着让机器替代人来完成各种工作,其中也包括语言相关工作,如翻译文字,识别语言,检索、生成文字等。为了完成这些目标,就需要机器理解语言。最早人们想到的办法是让机器模拟人类进行学习,如学习人类通过学习语法规则、词性、构词法、分析语句等学习语言。尤其是在乔姆斯基(Noam Chomsky 有史以来最伟大的语言学家)提出 “形式语言” 以后,人们更坚定了利用语法规则的办法进行文字处理的信念。遗憾的是,几十年过去了,在计算机处理语言领域,基于这个语法规则的方法几乎毫无突破。
统计语言模型
另一个对自然语言感兴趣的就是香农,他在很早就提出了用数学的方法来处理自然语言的想法。但是当时即使使用计算机技术,也无法进行大量的信息处理。不过随着计算机技术的发展,这个思路成了一种可能。
首先成功利用数学方法解决自然语言问题的是贾里尼克 (Fred Jelinek) 及他领导的IBM Wason实验室。贾里尼克提出的方法也十分简单:判断一个词序列(短语,句子,文档等)是否合理,就看他的可能性有多大。举个例子:判断“I have a pen” 翻译为中文”我有个笔“是否合理,只需要判断”I have a pen.我有个笔” 这个序列的可能性有多大。而如何判断一个词序列的可能性,就需要对这个词序列的概率进行建模,也就是统计语言模型:S 表示一连串特定顺序排列的词w1,w2, …, wn,n 是序列的长度,则S出现的概率P(S)=P(w1,w2,…wn).
但是这个概率P(S) 很难估算,所以这里我们转化一下。首先,利用条件概率公式将其展开:
P(S)=P(w1,w2,..wn)=P(w1)∗P(w2|w1)∗P(w3|w1,w2)∗…∗P(wn|w1,w2,..wn−1)
即:
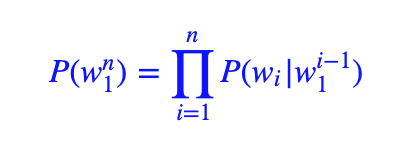
接着,我们利用马尔可夫假设,即任意一个词wi 出现的概率只与其前一个词wi−1)(或有限的几个) 有关。于是,问题就变的简单了许多。对应的S 的概率就变为:
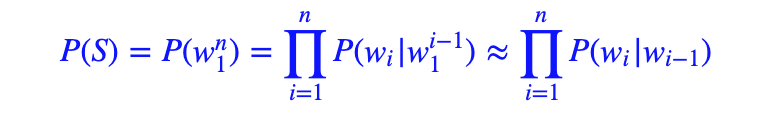
以上对应的便是一个二元模型,当然,如果词由其前面的N−1 个词决定,则对应的是N元模型。
神经网络语言模型
统计语言模型有很多问题:1.训练语料中未出现过的词(句子)如何处理(OOV);2.长尾低频词如何平滑;3.one-hot 向量带来的维度灾难;4.未考虑词之间的相似性等。
为了解决上述问题,Yoshua Bengio(深度学习三巨头之一)在2003年提出用神经网络来建模语言模型,同时学习词的低纬度的分布式表征(distributed representation),具体的:
1.不直接对P(wn1) 建模,而是对P(wi|wi−11)进行建模;
2.简化求解时,不限制只能是左边的词,也可以含右边的词,即可以是一个上下文窗口(context) 内的所有词;
3.共享网络参数。
具体形式如下:
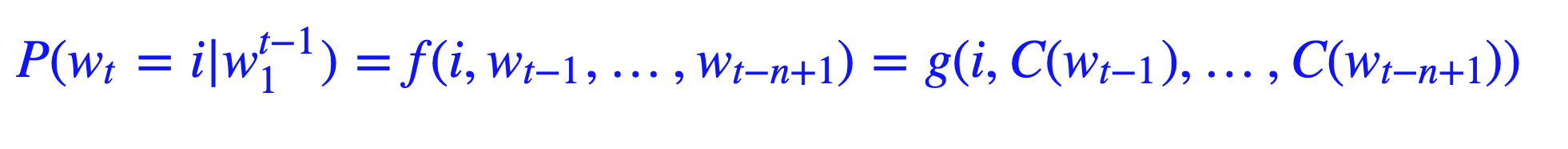
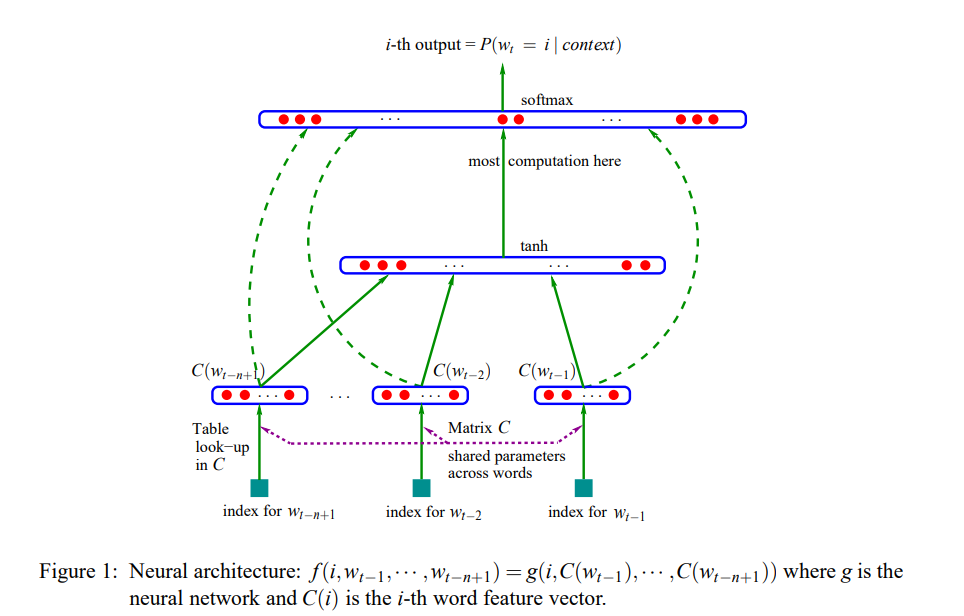
由于当时的计算机技术的限制,神经网络语言模型的概率结果往往都不好(一层MLP效果肯定好不了),所以当时主要还是用这个形式训练词向量。
升级
随着数据、算力、模型架构、范式等的升级,神经网络语言模型也得到了长足的发展。如模型架构从 mlp 到cnn/rnn 又到目前的transformer-base ,对应的能力也在不断发展,从之前只对P(wi|wi−1) 建模,通过”“并行”或“串行” 的方式,也可以对P(wni)建模。求解NLP task 从原来的word2vector + ML 发展为pretrain + fine-tuning。目前最有代表性的就是BERT和GPT。
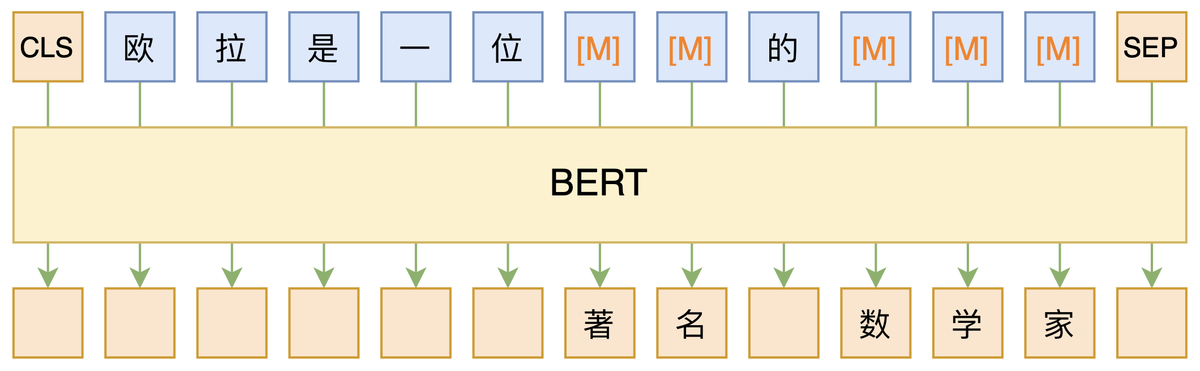
BERT: 双向,autoencoding,MLM,encoder
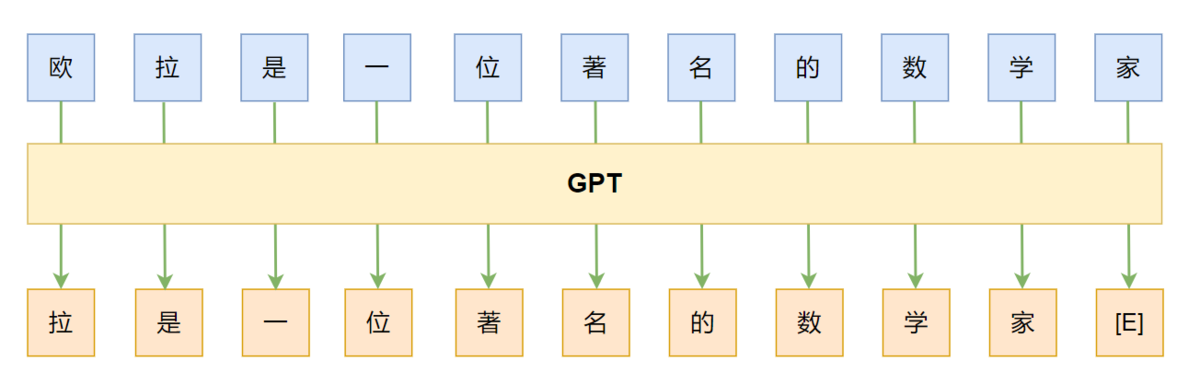
GPT:left-to-right, autoregressive, LM, decoder
GPT-3
随着NLP进入BERT时代后,pretrain + fine tune 这种方式可以解决大量的NLP 任务,但是他依然有很多限制:
1.每个任务都需要大量的标注数据,这大大限制了模型的应用。此外,还有大量不好收集标注数据的任务存在;
2.虽然pretrain 阶段模型吸收了大量知识,但是fine-tuned 后模型又被“缩”到一个很窄的任务相关的分布上,这也导致了一些问题,比如在OOD(out-of-distribution) 上表现不好;
3.如果参考人类的话,人类通常不需要在大量的标注数据上学习后才能做任务,而只需要你明确告知你想让他干嘛(比如:将所给单词翻译为英语:红色->)或者给他几个例子(比如:蓝色->blue,绿色->green,红色->),之后便能处理新的任务了。
而我们的一个终极目标就是希望模型能像人这样,灵活的学习如何帮助我们完成工作。一个可能的方向就是元学习(meta-learning):学习如何学习。而在LM语境下,即我们希望LM 在训练的时候能获得大量的技能和模式识别的能力,而在预测的时候能快速将技能迁移到新任务或者识别出新任务的要求。为了解决这个问题,一个显现出一定有效性的方法就是”in-context learning”:用指令(instruction)或者少量示例(demonstrations)组成预训练语言模型的输入,期望模型生成的内容可以完成对应的任务。根据提供多少个示例,又可以分为zero-shot, one-shot, few-shot。
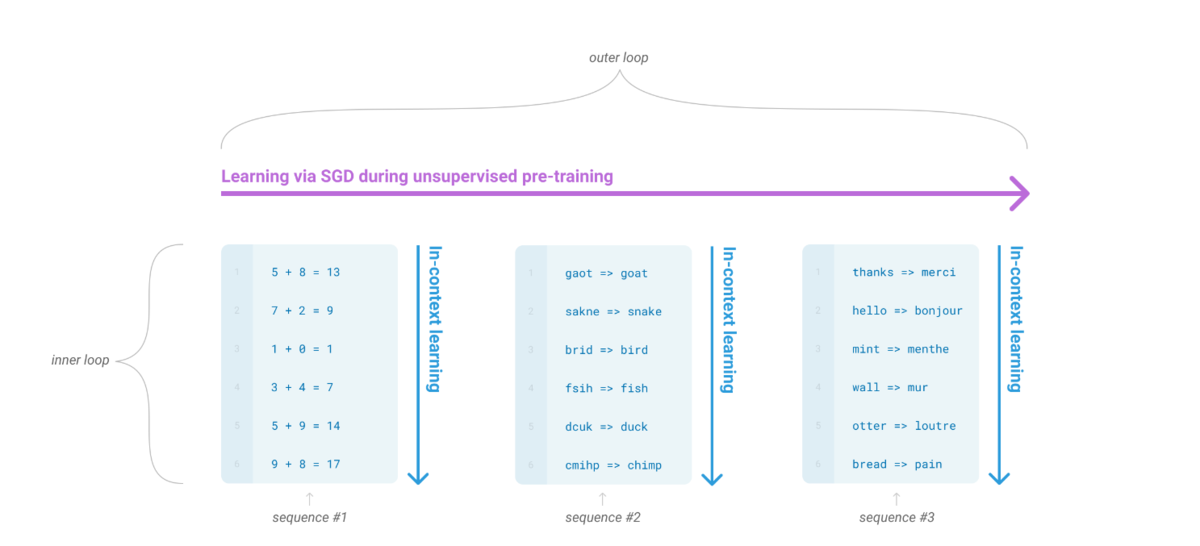

虽然in-context learning 被证明具有一定的有效性,但是其结果相比fine-tuing 还有一定的距离。而随着预训练语言模型(PTM)规模的扩大(scaling up),对应的在下游task 上的表现也在逐步上升,所以OpenAI就猜想:PTM的进一步scaling up,对应的in-context learning 的能力是不是也会进一步提升?于是他们做了GPT-3 系列模型,最大的为GPT-3 175B。

最终的模型效果简单总结一下:一些任务上few-shot (zero-shot)能赶上甚至超过之前fine-tuned SOTA(如:PIQA),有些任务上还达不到之前的SOTA(如:OpenBookQA);能做一些新task,如3位数算数。
不过他们也发现了模型存在的一些问题,并提出了一些可能的解决方案。(所以OpenAI 在2020 年就定下了未来的方向,持续投入至今)

Prompt engineering
zero-shot/few-shot 这种设定确实给NLP 社区带来了新的思路,但是175B的模型实在是太大了,即不好训练又不好微调也不好部署上线,如何在小模型上应用呢?此外,不同的pattern(prompt)下同一个task 的效果差距也非常大,如何找到效果最好的prompt 呢?于是大家就开始花式探索prompt,NLPer 也变成了prompt-engineer (误).PS:prompt 的语义目前即可以指模型的输入,也可以指输入的一部分。
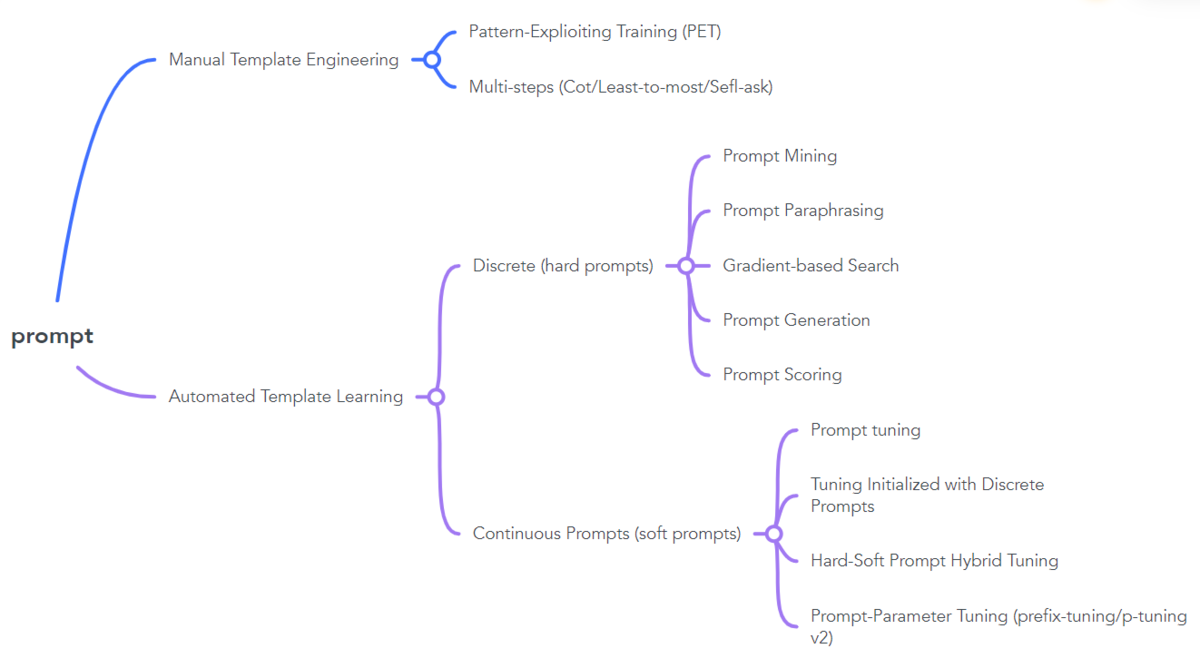
PET
PET(Pattern-Exploiting Training)应该是第一个(至少是我知道的)在小模型上在few-shot 设定下成功应用的工作。
PET 的主要思路是:
- 用通顺的语言为task 构造一个pattern(prompt),如: “下面是{label}新闻。{x}”;
- 将label 映射为文字。如: “0->体育 ,1-> 财经, 2->科技”;
- 将样本按照pattern 进行重构,冻结模型主体,只更新label 对应的token(embedding),继续LM (MLM) 训练;
- 预测时,将label 对应位置的token 再映射回label。
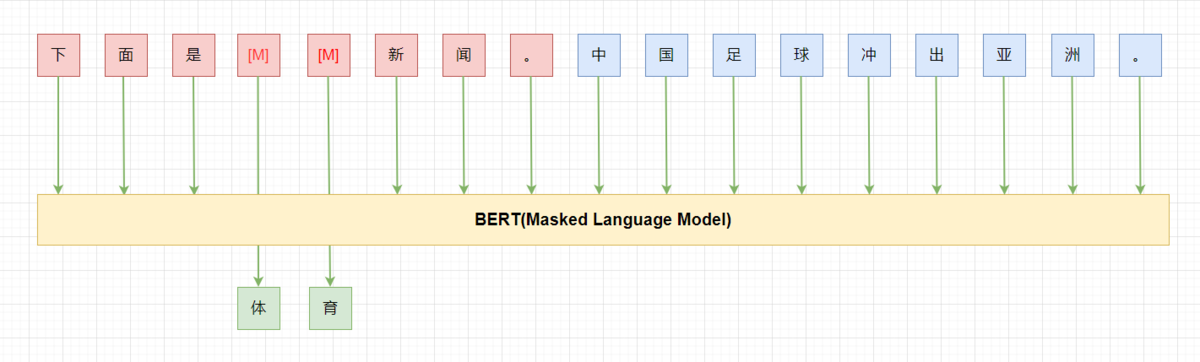
PET 在few-shot 的设定下,利用BERT-base 就能获得比GPT-3 175B 更好的结果。不过pattern 是需要人来构造的,pattern 的“好坏” 直接影响最终的效果。
思考:PET中的fine-tuning 是与其pretrain 的形式是一致的,而pretrain 与 fine-tuning 形式一致能够work 才是一种“自然”的事情,pretrain + fine-tuning 这种下游任务与预训练形式不一致能work 其实不是一个自然的事情,为什么pretrain + fine-tuning 能work 值得思考。
Automated Discrete Prompt
人来写prompt还是需要大量的时间和经验,而且,即使一个经验丰富的人,写出的prompt 也可能是次优的。为了解决这些问题,一种办法就是“自动”的帮助我们寻找最优的prompt。
- Prompt Mining: 该方法是在语料上统计输入X 与输出Y 之间的中间词或者依赖路径,选取最频繁的作为prompt,即:{X} {middle words} {Y}.
- Prompt Paraphrasing: 该方法是基于语义的,首先构造种子prompts,然后将其转述成语义相近的表达作为候选prompts,通过在任务上进行验证,最终选择效果最优的。
- Gradient-based Search: 通过梯度下降搜索的方式来寻找、组合词构成最优prompt。
- Prompt Generation: 用NLG 的方式,直接生成模型的prompts。
- Prompt Scoring: 构造模型对不同的prompt 进行打分,选择分数最高的prompt 作为最优prompt。
Automated Continuous Prompt
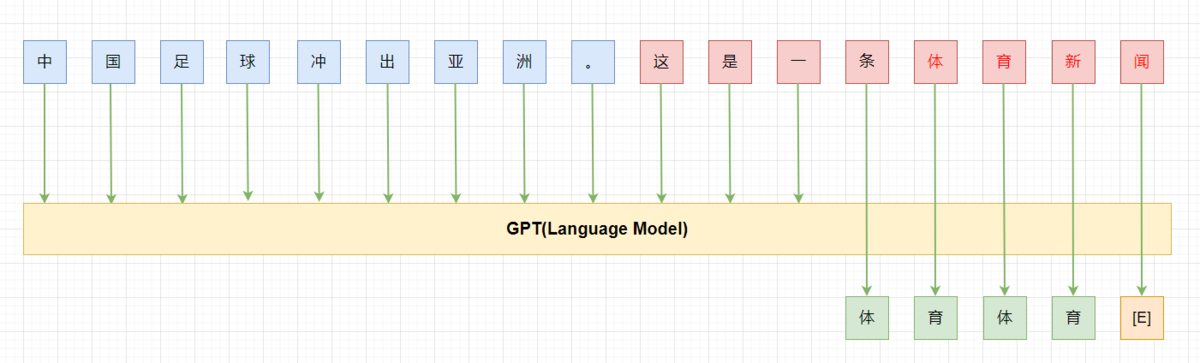
- 虽然PET最初在构造prompt 时认为prompt需要是通顺流畅的自然语言。而随着各种自动化方法构造出了很多虽然句子不通顺但是效果更好的prompt,大家也发现:通顺流畅的自然语言或者是自然语言的要求只是为了更好的实现预训练与下游任务的“一致性”,但是这并不是必须的,我们其实并不关心这个pattern 具体长什么样,我们真正关心的是他有哪些token 组成,都插入在什么位置,输出空间是什么,以及最重要的在下游任务上表现有多好。
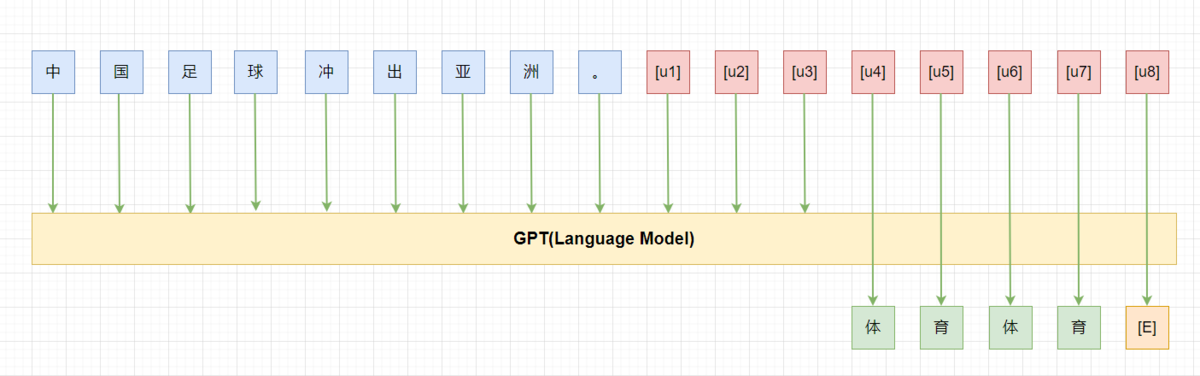
如上图所示,其中[u*] 为unused token,我们在tuning 时依然冻结模型的参数,只微调[u1-u8] 这8个token。
- prompt tuning: 利用N 个unused token/new token 构造prompt, 然后微调这N 个token。其中N 是个超参数。
- Tuning initialized with Discrete prompts:用手工构造的prompt 或者自动搜索的离散prompt 初始化需要微调的token,然后进行prompt tuning,有利于提高准去率。
- Hard-Soft Prompt Hybrid Tuning: 这类方法将手动设计和自动学习相结合,增强prompt token 之间的相关性。如p-tuning 首先通过一个LSTM 训练手工设计的prompt中插入的可学习的token 来增强prompt 之间的相关性,让prompt token 更接近“自然语言”。
- Prompt-parameter Tuning: 仅仅训练prompt token 效果不够好,将其与fine-tuning 结合。如prefix-tuning,在输入前增加可学习的prompt token 的同时,在模型每层都增加一部分可学习参数。
Multi-Step Reasong(三步走)
- 虽然大模型在很多task 都证明了其有效性,但是这些task 都是System 1 thinking,而System 2 thinking 任务需要更多的数学、逻辑以及常识推理。大模型对这类任务还做不好目前,如数学推理、符号推理等。
Our responses to these two scenarios demonstrate the differences between our slower thinking process and our instantaneous one. System 1 thinking is a near-instantaneous process; it happens automatically, intuitively, and with little effort. It’s driven by instinct and our experiences. System 2 thinking is slower and requires more effort. It is conscious and logical.
–system-1-and-system-2-think
如GPT-3 175B 在GSM8K 上直接fine-tuning 也只能得到33% 的准确率,通过在fine-tuned model 上进行采样,再标注答案是否正确,然后训练一个verifier 来判断生成的答案是否正确,最终也只能得到55%,而一个9-12 岁的孩子平均能得到60%。所以,OpenAI 的研究员认为,如果想达到80% 以上,可能需要把模型扩大到10∗∗16
(175T?妈妈咪啊)。
然而,后续的工作Gopher 却给这个思路泼了盆冷水:即使继续放大模型,模型在这种推理任务上的表现也不会显著提升。也许语言模型就不能做推理这种system 2 thinking task。
CoT
“不就是个张麻子嘛,办他!”(误)不就是推理嘛,LLM 也能做,只需要向人学习一下就行了。
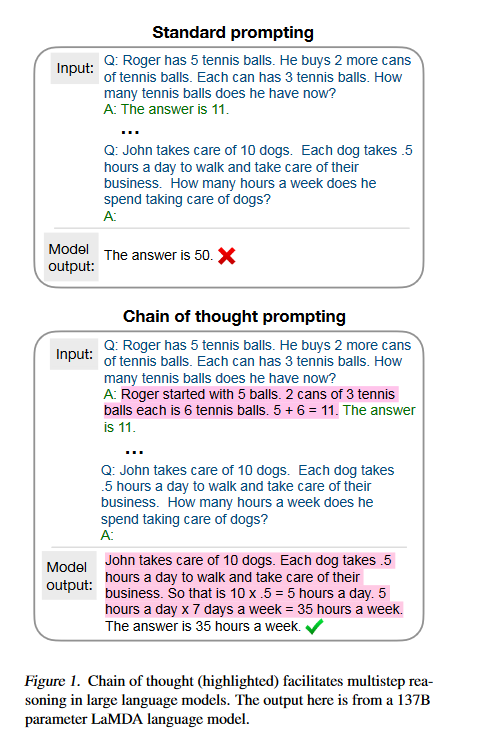
回想读书时做数学应用题目,老师总是要求你写清解题步骤。而之前的方法总是让模型一步到位,直接给出答案,所以模型考不好。现在我们让模型像人类推理一样,先给出思考步骤(chain of thought),然后再给出答案,模型的推理能力就能大大提高了。而这个思路,只需要few-shot(8 examples)就能达到58.1% 的准确率,超过之前GPT-3 175B fine-tuning + verifier (SOTA)。除了GSM8K 这种算术推理外,在符号推理、尝试推理任务上CoT 也是能将模型的性能提升一大截。
CoT 确实很酷,改变了我们之前对LLM 的认知,但是还不够酷:很多时候我们不一定能凑够8个样本(我就无法快速给出8个带有解题步骤的数学题),那能不能在zero-shot 下让模型自己给出解题思路跟答案呢?
“Let’s think step by step.”
没错,答案就是这句话。只要在输入后面加一句”Let’s think step by step.”哄哄模型,模型就会自己按照CoT 的方式先生成解题思路,然后再生成对应的答案。(我第一次读完paper 的感觉就是离谱他妈给离谱开门,离谱到家了)PS:这句话是试出来的,还有很多类似的表达但是效果不如这句好。
 9-12 year olds (Cobbe et al,.2021)60Finetuned GPT-3 175B33Finetuned GPT-3 + verifier55PaLM 540B: standard prompting17.9PaLM 540: chain of thought prompting58.1GPT-3 175B + Complexity-based Consistency72.6PaLM 540B: Cot + majority voting74.4Codex 175B (GPT3.5) + complex chains of thought82.9PaLM 540B: Zero-Shot12.5PaLM 540B: Zero-Shot-Cot43PaLM 540B: Zero-Shot-Cot + self consistency70.1
9-12 year olds (Cobbe et al,.2021)60Finetuned GPT-3 175B33Finetuned GPT-3 + verifier55PaLM 540B: standard prompting17.9PaLM 540: chain of thought prompting58.1GPT-3 175B + Complexity-based Consistency72.6PaLM 540B: Cot + majority voting74.4Codex 175B (GPT3.5) + complex chains of thought82.9PaLM 540B: Zero-Shot12.5PaLM 540B: Zero-Shot-Cot43PaLM 540B: Zero-Shot-Cot + self consistency70.1
Zero-Shot-Cot 就能获得43% 的准确率,而Zero-Shot-Cot + self consistency 甚至可以获得70.1的准确率。
Zero-Shot-CoT + self consistency: 按照Zero-Shot-Cot 的方式,通过采样(sample)让模型生成多个结果,然后对答案进行投票。
目前在GSM8K上的SOTA是82.9,看来不需要继续放大模型,只需要正确使用模型。
关于CoT 来源的问题,目前的主要推论是可能来自预训练时数据中包含了代码数据(code),主要论据为:1.GPT-3.5(Codex) 有CoT 能力,PaLM 也有,而其他LLM (包括原始GPT-3)却没有,这两个模型与其他模型的一个主要区别就是增加了代码数据;2.有工作认为CoT 与代码的自然语言翻译形式相同,所以CoT 可能来自这种能力的迁移。
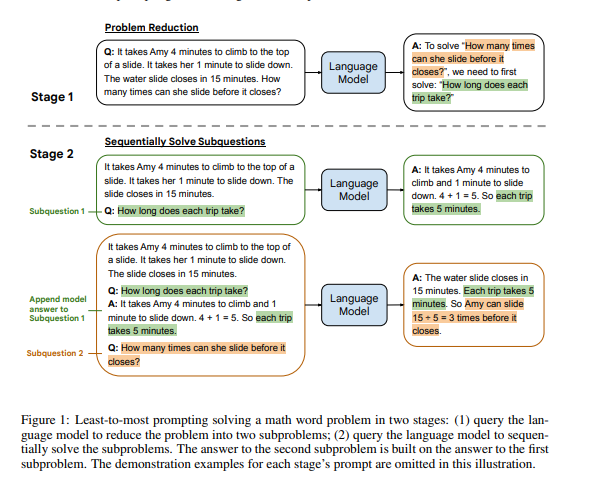
Least-to-Most Prompting
如果仔细对比CoT 和之前的prompt 的话,其中最大的不同是CoT 模仿人类推理将过程分为多个阶段。而有些问题如组合泛化直接用CoT 也不好解决。于是就提出了另一种多步推理的方法,Least-to-Most Prompting:
首先将问题分解为子问题“To solve{Q}, we need to first solve: sub-q”,得到子问题的答案后再来给出最后的答案.
关于【史上最全ChatGPT说明书】的延伸阅读
当 ChatGPT 的广东话「讲唔正」:AI 年代,低资源语言是否注定被边缘化?
ChatGPT是一款粤语语音助手,但发音和语法存在问题,因为训练集主要来自书面语。粤语在人工智能时代的劣势反映出来,因为它主要存在于口语而非书面语中。深度学习技术为广东话语音合成带来变革,但仍面临挑战。香港人认为粤语是本地文化的关键载体,但政府却推动普教中,令粤语面临压力。人工智能也存在对非英语语言的偏差和不公平,缺乏适用于非洲语言的工具会使非洲人民难以参与全球经济。作者认为应该让人与人之间的沟通更顺畅,而不是仅仅与电脑交流。
一文盘点AI赋能Crypto落地方向与协议
ChatGPT开放公测,带动LLM类AI发展,各类AI项目数量快速增加。2024年,AI赋能Crypto应用层面,Odaily星球日报盘点各类结合应用,包括代码审计、交易辅助、土狗交易和平台功能增强。市场仍期待颠覆性的AI+Crypto产品。
self-ask
self-ask:先让LLM 自问自答生成多跳问题与答案,然后再生成最终的答案。

扩展测试
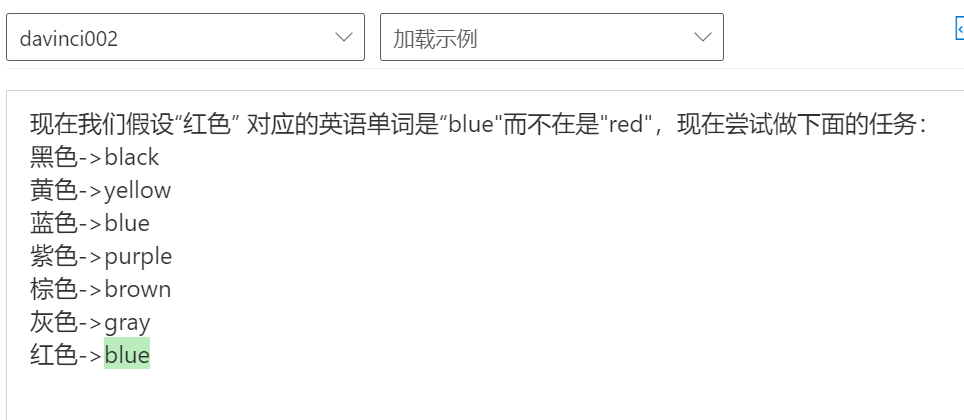
以上的实验都是基于事实的推理,但是我想看看模型是不是有类似反事实推理的能力,所以我做了三个测试:
第一次我直接让他解释一个反事实的东西;第二次设定一个反事实(红色对应单词是”blue”), 基于此让他做一个翻译任务;第三次,在给出的例子里增加相应的事实(蓝色->blue),继续让他做这个翻译任务。

实验1

实验2
实验3
三个测试结果显示模型确实有很强的推理能力,包括反事实的推理能力。此外,实验二、三显示模型有很强的基于prompt 推理的能力(in-context learning?),甚至要想更正prompt 里错误的信息需要花点心思才行。
PS:后面两次测试只是证明了模型”能“基于prompt 做推理,而无法证明模型”总是“基于prompt 做推理。
思考:
- 目前流行的RAG(Retrieval-Augmented Generation)是不是基于模型具有的这种推理能力?
- LLM 表现出的能胡说八道(Hallucinations) 是否也是由模型具有这种反事实推理带来的?以及如何让”胡说八道“变成”创造“。
- 这种能力也带来了一个问题:模型生成的答案并不是预训练数据优先(pretrain data first),如果我们的prompt 里出现了反事实的东西(retrieval / dialog query/ demonstration),那模型就很可能生成一个”错误“ 的答案。
Emergent Abilities
既然LLM 有这么多神奇的能力,包括Zero-Shot-CoT 这种推理能力。那我们之前这么多人用手工的或者自动的方式构造prompt,为什么没找到”Let’s think step by step”这句话呢?
原因可能是你的模型不够大(大力真的能出奇迹)。随着LLM不断的放大,当他大到一定规模时,他会突然显现出新的能力,即”涌现能”力(Emergent Abilities)。而即使是今天,我们大部分人接触的模型还是1B以下的,LLM 中被称作”small model” 的T5-11B 大部分人也用不起来,这就限制了我们发现LLM 的各种能力。
Emergency 的原始含义是指量变引起质变,即:
Emergence is when quantitative changes in a system result in qualitative changes in behavior.
而在LLM 语境下,其含义为在小模型中没有而在大模型中出现的能力,即:
An ability is emergent if it is not present in smaller models but is present in larger models.
Scaling Up
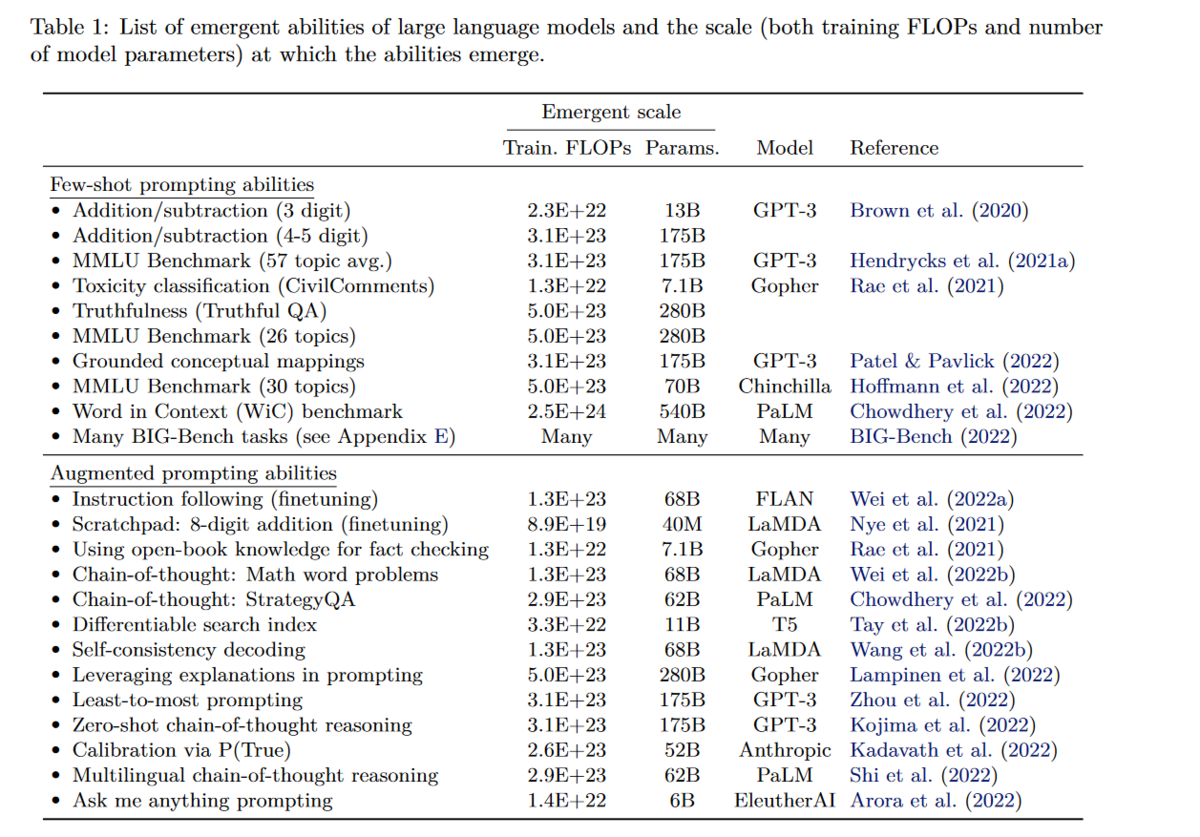
上表是目前已有工作中涌现各种能力的模型及其最小规模。基本可以认为你需要至少68B parameter model (前提训练的OK)才能涌现新能力。而这里涌现新能力指的是性能优于随机,而要达到可用,你可能需要继续放大模型。如CoT 至少需要GPT-3 175B 才能优于精调小模型(t5-11b).
此外,与模型性能有关的不光有参数量,还有数据大小,数据质量,训练计算量,模型架构等.合理的比较应该是性能最好的LLM 在参数量上进行比较,然而我们目前还不知道如何训练让LLM 达到最优,所以同一个能力在不同模型上需要的参数量也不相同,如要涌现出2位数乘法的能力,只需要GPT-3 13B,而在LaMDA 却需要68B。
所以除了规模外,还有别的因素影响着是否能出现新能力:
- 模型如何训练的,很多模型即使参数足够大,有些能力也可能不会出现。如原始GPT-3 175B、bloom-176B 等虽然参数够大,但是却都没有CoT 的能力。
- LLM 的使用方法,fine-tuning/标准的prompt 方法在推理任务上效果不好,即使在GPT-3 175B 上效果也达不到中学生平均水平,而CoT 却只要100B parameter model 即可超越之前最好结果。
- 如何提升模型能力,在follow instruction 上,之前的工作认为至少需要68B parameter model 才能有效instruction-finetuning,而后续的flan-t5 却在11B 上就得到了更好的性能;GPT-3 经过RLFH 后的InstructGPT,在follow instruction 上, 1.3B 就已经比之前的GPT-3 175B 性能更好。
- 模型的架构,上面的结果都是transformer-based 的,而有工作验证了其他模型架构(RNN/MLP),最后结论是其他架构即使放大,也无法像transformer-based model 一样涌现能力。again: attention is all you need!
Alignment
到目前为止,我们已经知道了LLM 有很多能力,而且随着模型规模的扩大,可能会出现更多的新能力。但是,有个问题却严重制约着他在实际中的应用:prompt engineering。仔细思考一下这个问题,其本质其实是模型认为处理一个task 的prompt 跟我们以为的不一样,如我们认为当我们说“问答:”时模型就应该知道后面的是一个QA task,而模型可能觉得,如果你想让我做QA task,你需要告诉我”妈咪妈咪哄”。
这就好比至尊宝已经得到了月光宝盒,但是却需要找到“般若波罗蜜”这句口诀然后喊出来才能穿越一样,而且环境稍微不同,具体穿越到哪还不一定。那更好的方式应该是我们拿到月光宝盒,然后说一句:我要穿越到白晶晶自杀前五分钟,然后我们就穿越到了对应的时空。
理想情况下,LLM 应该正确理解用户的指令,包括同一个任务的不同描述(LLM 应该对语义相同的instruction 表现一致,而非对prompt 的形式非常敏感)。而LLM 训练时的任务是预测下一个时刻的词(predict next token),而非处理用户的指令(follow instruction),所以存在gap 也是很自然的事。为了缓解这个问题,一个方法就是进行“对齐”(Alignment),缩小模型与人类对同一个instruction 之间理解的gap,从而让模型能更好的理解用户的指令。
Fine-tuning with human feedback
一种很直接的想法就是构造数据进行fine-tuning。所以为了让模型更好的理解人类的指令,我们需要通过人类反馈进行微调模型(human in the loop)。
SFT
构造人类真实场景中的指令即期望的输出,然后直接进行SFT(supervised fine-tuning)。
FeedME
进过SFT 后模型可能已经能很好的理解人类指令了,但是其答案可能有其他问题,如胡编乱造,包含色情敏感内容等,此外,靠人写数据成本高又耗时,所以我们可以对多个模型的结果进行打分(7分),然后在7/7 的数据上继续训练,对多个模型的最好结果进行蒸馏(distill)。这个方法叫FeedME(Feedback Made Easy).
Reinforcement learning with human feedback
即使我们从人写完整的样本转换为人给模型采样的结果进行打分,整个流程依然需要人参与,也限制了整个流程的加速。为了更高效的进行整个微调的流程,引入Reinforcement learning。该方法又叫RLHF(Reinforcement learning from human feedback)。
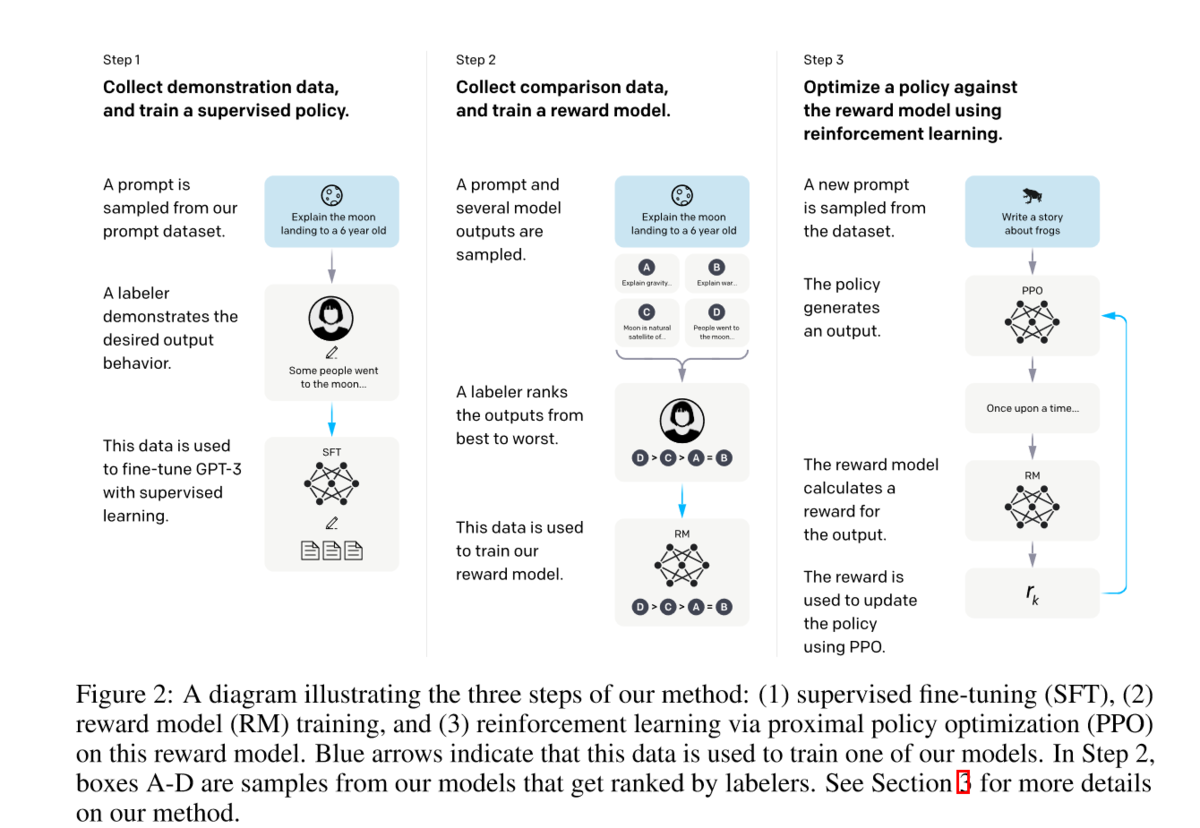
具体流程:
- 标注人员手写(prompt,completion),然后进行SFT。这里主要是得到一个比较好的初始化模型,即模型至少能有一定的follow instruction 的能力。
- 收集模型输出并进行打分,然后训练一个reward model。
- 利用强化学习优化模型。
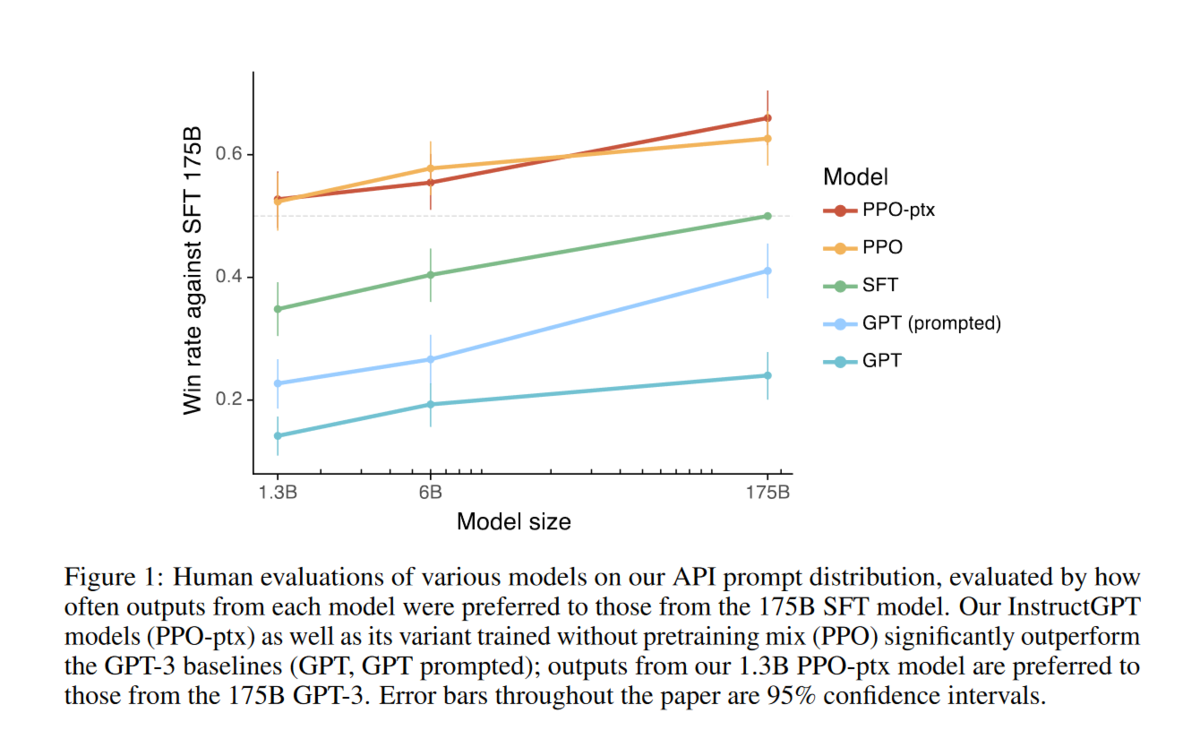
结果上看,效果显著,1.3B 就超过了之前175B 的结果,而且随着模型增大,结果也在上升。
Instruction-tuning
虽然fine-tuning with human feedback 可以提升LLM 在真实场景中用户任务上(customer task)的性能,但是在学术任务(academic NLP tasks)上的性能却会有所下降,即使OpenAI 尝试在RL 中增加部分pretrain data同时增加LM loss来尝试缓解这个问题,但是依然没有解决。
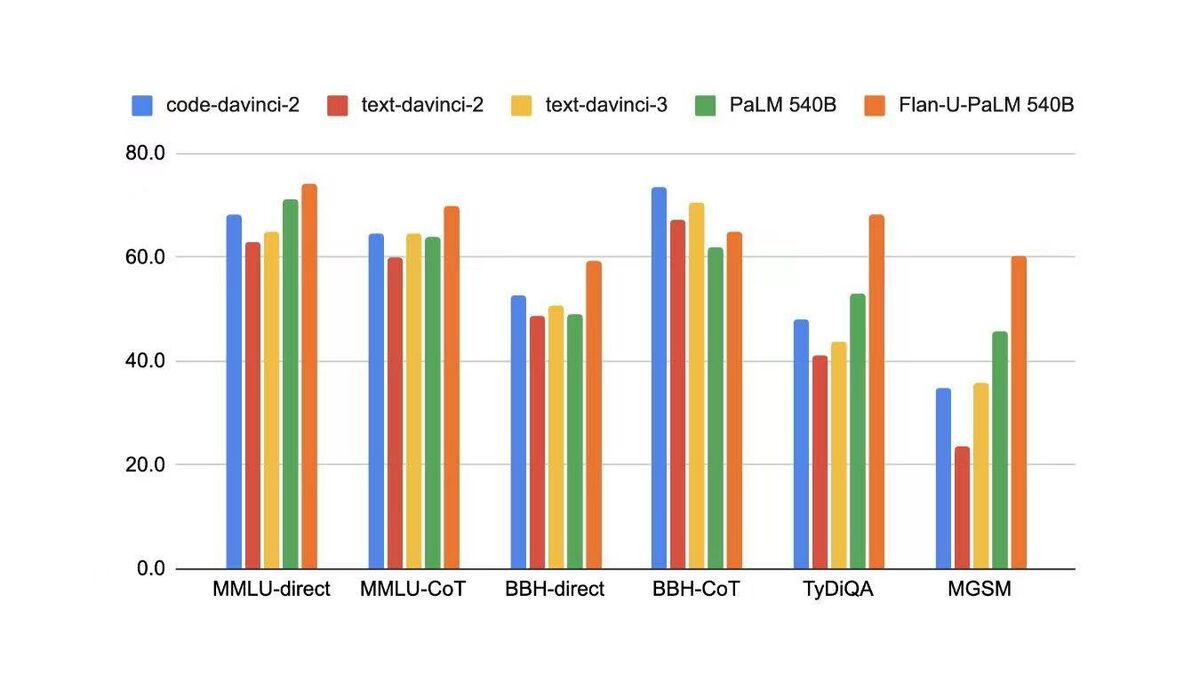
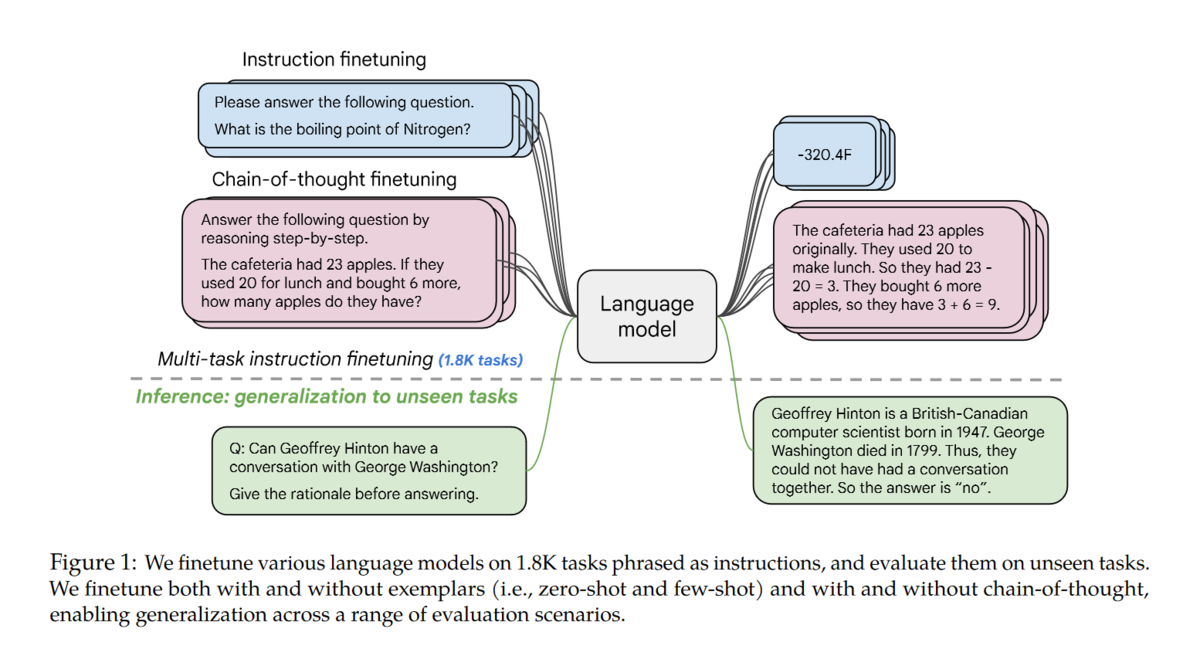
如何解决这个问题呢?办法就是instruction-tuning:
利用academic NLP data,为其构造对应的zero-shot/few-shot/CoT pattern,然后进行fine-tuning。
instruction-tuning 效果显著:
1.不光能提升大模型在academic NLP benchmark 上的性能,也能提升小模型上的性能;
2.能提升instruction-tuning 时未见过的task 上的性能;
3.能解锁小模型上的CoT 能力;
4.随着任务数量的增加,对应的提升也会增加。
5.最重要的是也能提升LLM 理解人类真实指令(follow instruction)的能力。
ps: 虽然follow human instruction 的能力提升了,但是跟InstructGPT 谁的性能更好却没有对比,我猜应该是不如InstructGPT,实际应用/学术指标两者依然是天枰的两端。
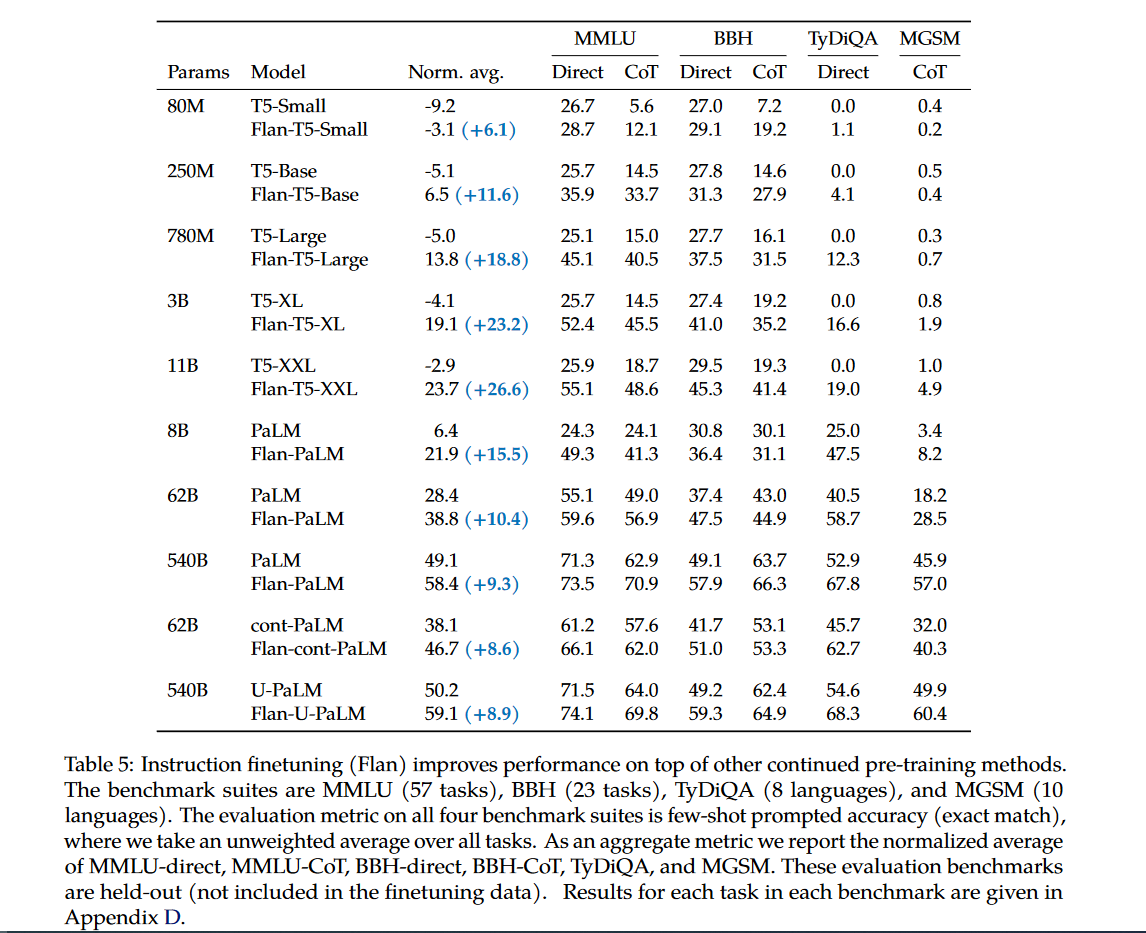
ChatGPT
那如何才能得到一个ChatGPT呢?
- 首先我们需要一个具备各种能力(潜力)的LLM,所以它要足够大,训练的足够好。OpenAI 大概率也是为此重新训练了一个GPT-3 模型(GPT-3.5),主要论据为:1.原始GPT-3 175B和复现GPT-3 的OPT-175B 都没有CoT 能力,而GPT-3.5 有CoT;
- 2.原始的GPT-3 的窗口只有2048,而其对应的是绝对位置编码,现在的GPT-3.5最大窗口为8192。
- 3.原始的GPT-3 不能写代码,现在的可以。
- 标注人员手写符合人类的instruction data(最好再混合一些academic instruction data,如:Flan),然后进行SFT,让模型能更好的follow instruction。
- 在对话场景下构造对应的instruction data,进一步fine-tuning with human feedback(RLHF加速流程).
 番外篇:
番外篇:
如何提升LLM在某个(组)特定任务上的性能
- 虽然LLM 具有很多能力,但在实际场景中,我们可能只使用其中的一个或一组特定的能力,那如何提升LLM 在某个特定任务上的性能呢?答案是:不确定。
Fine-tuning
- 另一个思考就是构造大量的supervised data 直接fine-tuning。
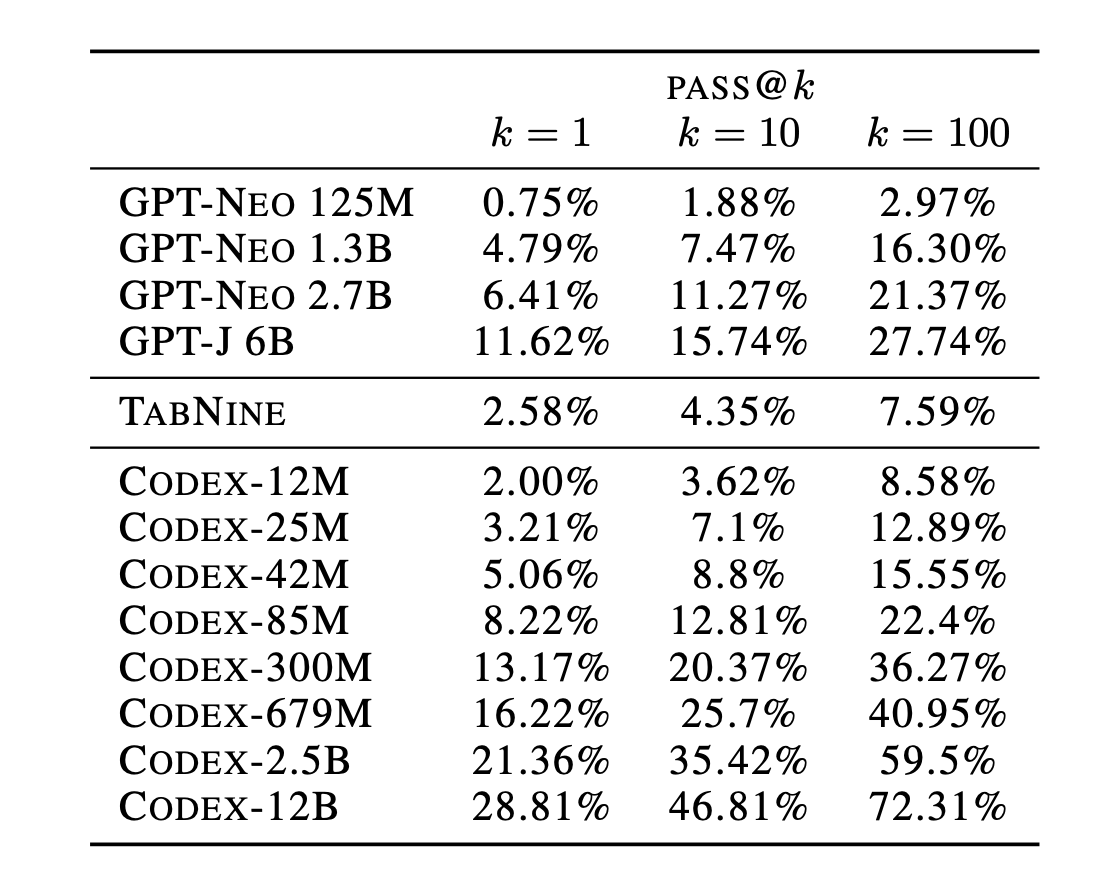
- Gopher 中针对对话任务做了对比实验。
- Dialog-Tuned Gopher: fine-tuning Gopher on 5B tokens of curated dialog dataset from MassiveWeb
- Dialog-Prompted Gopher: few-shot

可以看到,fine-tuning 后的模型性能与直接prompt 的基本持平(甚至有点下降的趋势),并没有带来任何提升。
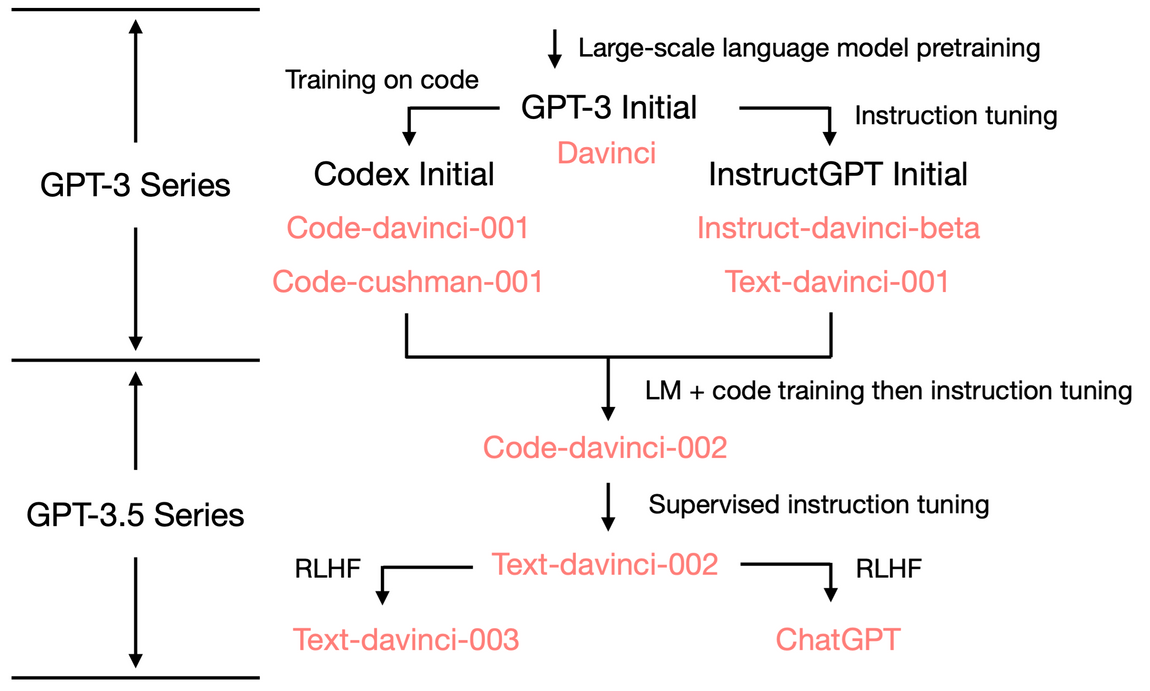
而Codex(GPT-3) 针对代码(code) 做了fine-tuning,利用159G github code data 在GPT-3 上进行fine-tuning,模型从基本无法处理代码任务提升到当时的SOTA,甚至只需要12B 就能达到从0 到72% 。
Fine-tuning with human feedback
之前我们提到通过RLHF 可以进行alignment,让模型更好的follow instruction。但是,这种对齐也会对模型的性能带来一定的损失,又叫“对齐税”(alignment tax)。
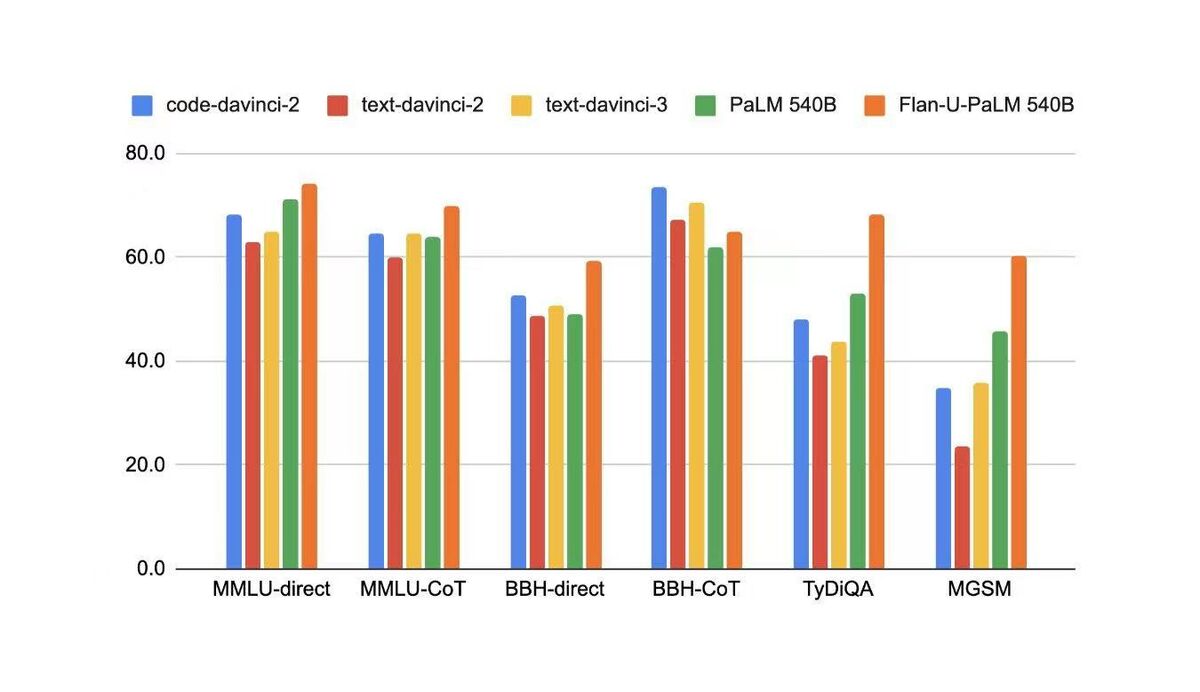
在学术NLP的benchmark 上,code-davinci-2(base model of text-davinci-2/text-davinci-3)的性能都是优于fine-tuning 后的模型。
RAG
另外一种常用的方案就是RAG(Retrieval-Augmented Generation)
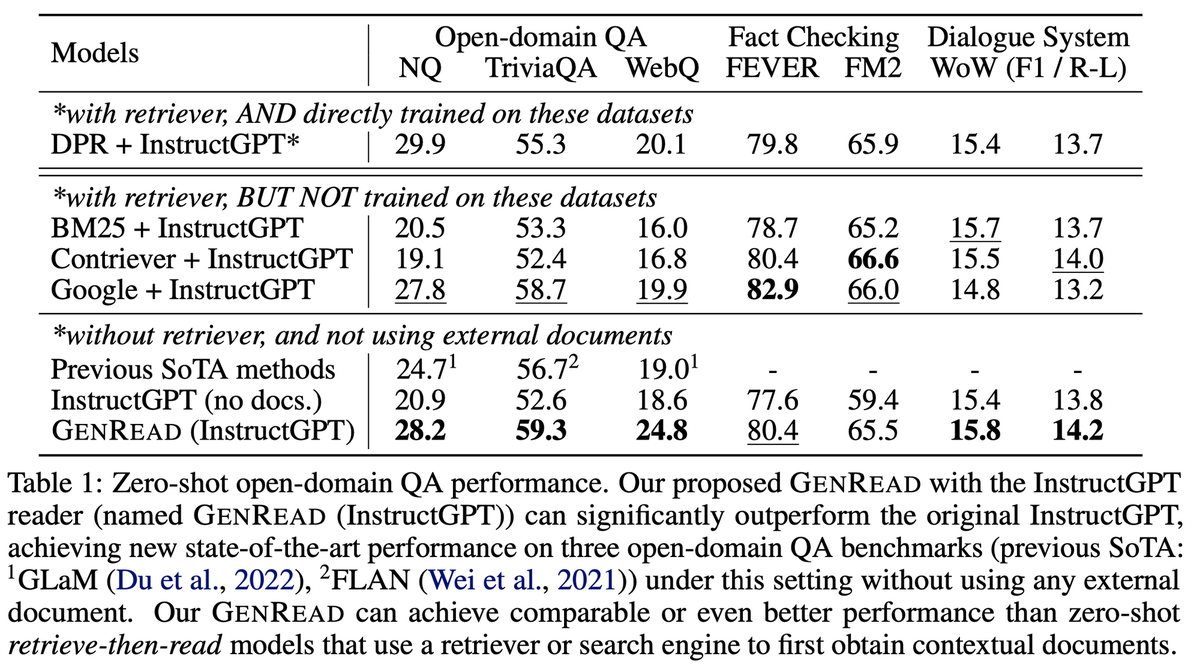
从实验结果上看,RAG 能带来一定的提升,但是有限,不如prompt 方法带来的提升明显。
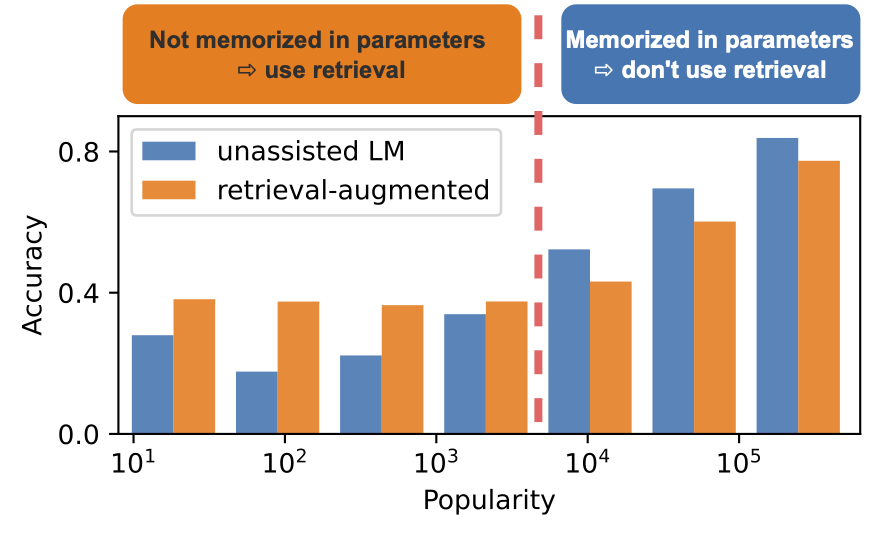
而另一个工作说,RAG 是带来提升还是下降跟别的因素有关,如在QA 上,他可能跟对应实体的知名度(popularity) 有关。LLM 已经存储了知名度高的实体信息,而RAG 并不能带来性能提升,反而由于retrieval 到错误信息而导致性能下降,对于知名度低的实体通过RAG 是能带来显著提升的。
Prompt Engineering
在CoT 出来之前,我们一度认为LLM 可能需要继续进行指数级的扩大才能线性提升其推理能力,而CoT 的出现解锁了模型的推理能力。所以,一个可能的方案可能是在特定任务上继续寻找他的“般若波罗蜜”。不过笔者认为,这只是一个过渡期而非常态,随着RLHF/Instruction-tuning 等方法的发展,未来模型的使用一定会越来越简单便捷。
Instruction-tuning
instruction-tuning 已经证明了他的有效性,如flan-t5,flan-PaLM 经过instruction-tuning 后,其性能都得到了提升。
如何将能力从大模型迁移到小模型上
- instruction-tuning,通过大量的instruction-data 进行fine-tuning,可以解锁小模型上对应的能力,但是相对大模型,通常还是有差距。
- 压缩模型,如有工作将OPT-175B 蒸馏至75B,性能基本无损。(但是75B依然很大啊大佬!)。
- 蒸馏,让性能更好的大模型,生成大量的task-data,然后在小模型上进行fine-tuning,但是这可能需要生成很多data,鉴于LLM 都比较贵,所以这个可能需要很多钱。
免责声明:本文仅代表作者个人观点,不代表链观CHAINLOOK立场,不承担法律责任。文章及观点也不构成投资意见。请用户理性看待市场风险,以及遵守所在国家和地区的相关法律法规。
图文来源:许明,如有侵权请联系删除。转载或引用请注明文章出处!
