长推:解读Meta开源AI项目MMS创新点
对预训练的MMS(1B)模型进行微调来训练多语言语音识别模型。

原文作者:balconychy
原文来源:Twitter
注:原文来自@balconychy发布长推。
Meta开源的Massively Multilingual Speech太厉害了。 个人觉得最大的创新点是:大大减少语音标记数据时长要求。 对比Whisper:FLEURS基准的54种语言上将Whisper的单词错误率减少了一半以上,这还是在 在一小部分标记的数据上进行训练得前提下。 标记数据:whisper(680K) VS MMS (3K 和 45K)。
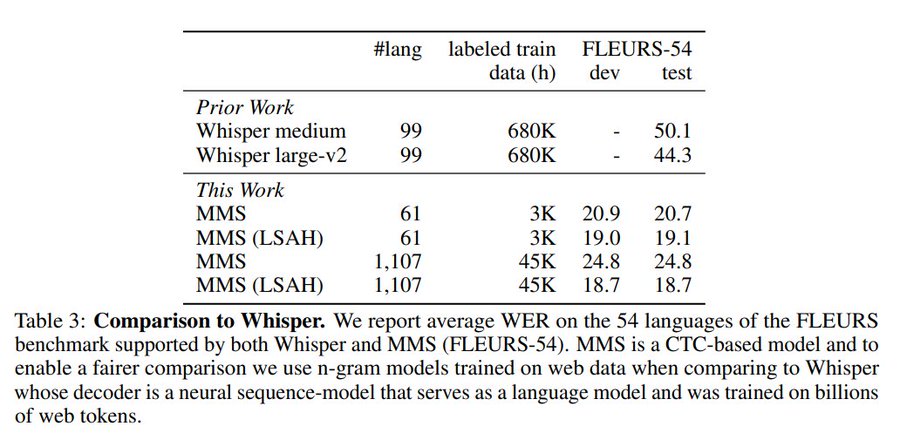
关键是:自监督预训练+微调。
这种模式看来是遍地开花:
-大语言:预训练(句子补全自监督训练)+微调(问题-答案样本监督学习)
-语音识别:预训练(无标记语音自监督训练)+微调(语音-文本样本监督学习)
直觉上看符合人类学习: 大量的无意义语音输入,然后在来一些有限的教学,小孩就能掌握语言。
具体训练过程:
关于【长推:解读Meta开源AI项目MMS创新点】的延伸阅读
走近BTC:理解BitVM所需的背景知识(1)
Delphi Digital发布了比特币二层技术研报,介绍了比特币Rollup和四大采用BitVM的项目。BitVM利用MATT思想,将复杂程序和数据存储在链下的Merkle树中,只发布Merkle Root到链上,实现比特币原生的验证欺诈证明。比特币脚本和Taproot以及预签名是实现这一方案的重要技术。P2SH交易类型中可以添加Script,比特币节点会验证公钥和公钥hash是否匹配,以及数字签名是否正确。隔离见证/SegWit升级解决了交易延展性问题,P2WSH功能与P2SH相似。Taproot可精简脚本内容,BitVM基于此构建复杂方案。下一篇文章将详细介绍Taproot、预签名等技术。
重新理解Marlin:AI下半场的可验证计算L0「新基建」
Marlin是一种可验证云计算服务,利用加密技术保证数据安全,为AI+Web3应用提供低延迟、低成本的解决方案。它基于TEE和ZKP技术,为用户提供通用化的云计算方案,并通过激励机制吸引节点为网络贡献资源。Marlin的愿景是成为AI世界的可验证通用L0,为Oracle预言机、ZK Prover系统、AI人工智能等应用场景提供节点算力和存储等网络资源服务。它可以为AI大模型训练提供安全的计算环境,并为多元化应用场景提供可验证计算中间件。在AI+Web3时代,Marlin有巨大的价值潜力,可能成为未来AI+Web3应用的关键基础设施。
预训练
使用自监督学习wav2vec 2.0在未标记语音数据上训练。类似句子补全,将语音随机屏蔽一段,然后猜屏蔽的部分。 在A100GPU上训练1百万个updates. MMS (0.3B) 48个GPU上按2.3小时每批次大小训练 MMS (1B)在64个GPU上按3.5小时每批次大小训练。
文本转语音子任务
对预训练的MMS(1B)模型进行微调来训练多语言语音识别模型。 在模型上添加线性层,映射到输出词汇表。
模型已经开源可以下载,包含底座和具体识别任务模型。支持微调。 https://github.com/facebookresearch/fairseq/tree/main/examples/mms…
免责声明:本文仅代表作者个人观点,不代表链观CHAINLOOK立场,不承担法律责任。文章及观点也不构成投资意见。请用户理性看待市场风险,以及遵守所在国家和地区的相关法律法规。
图文来源:balconychy,如有侵权请联系删除。转载或引用请注明文章出处!
标签:数据
")