ZKML与分布式算力:AI与Web3的潜在治理叙事
让AI形成真正的分布式群体共识机制

原文作者:Go2Mars Research
原文来源:GO2MARS的WEB3研究
关于ZKML:ZKML(Zero Knowledge Machine Learning)是一种机器学习技术,它结合了零知识证明(Zero-Knowledge Proofs)和机器学习算法,旨在解决机器学习中的隐私保护问题。
关于分布式算力:分布式算力是指将一个计算任务分解成多个小任务,并将这些小任务分配给多个计算机或处理器进行处理,以实现高效的计算。
AI与Web3的现状:失控的蜂群与熵增
在《失控:机器、社会与经济的新生物学》里,凯文·凯利曾提出过一个现象:蜂群会按照分布式管理,以群舞的方式进行选举决策,整个蜂群跟随在本次群舞中最大规模的蜂群成为一次事件的主宰。这也是墨利斯·梅特林克提到的所谓“蜂群的灵魂”——每一只蜜蜂都可以做出自己决定,引导其他蜜蜂进行证实,最后形成的决定真正意义上都是群体的选择。

熵增无序的规律本身就遵循热力学定律,物理学上的理论具象化是把一定数量的分子放入空箱,测算最后的分布概况。具体到人,由算法生成的群氓虽有个体的思维差异也能展现出群体规律,往往是因时代等因素被限制在一个空箱中,最后会做出共识性的决策。
当然,群体规律未必是正确的,但是可以代表共识,能够以一己之力拉起共识的意见领袖是绝对的超级个体。但大多数情况下共识也并不追求所有人人完全无条件的同意,只需要群体具有普遍的认同性。
我们在此并不讨论AI是否会将人类带入歧途,实际上这类讨论已然很多,不论是人工智能应用生成的大量垃圾已经污染了网络数据的真实性,还是因为群体决策的失误会导致一些事件走向更加危险的境地。
AI目前的状况带有着天然的垄断,比如大模型的训练和部署需要大量的计算资源和数据,而只有一小部分企业和机构具备这些条件。这些数以亿万计的数据被每个垄断所有者视若珍宝,不要提开源共享,就连互相的接入也是不可能的。
这就带来了极大的数据浪费,每一个大体量AI项目都要进行用户数据的重复收集,最后以赢家通吃——不论是并购还是卖出,做大个别巨形项目,还是传统互联网圈地跑马的逻辑。
很多人说,AI和Web3是两回事,没有任何联系——前半句是对的,这是两个不同的赛道,但后半句是有问题的,利用分布式技术限制人工智能的垄断终局,以及利用人工智能技术促进去中心化共识机制的形成,简直是天然的事情。
底层推演:让AI形成真正的分布式群体共识机制
人工智能的核心还是在于人本身,机器和模型不过是对人思维的揣测和模仿。所谓群体,实际上很难把群体抽象出来,因为每日所见的还是真实的个体。但模型就是利用海量的数据进行学习和调整,最后模拟出的群体形态。不去评价这种模型会造成什么样的结果,因为群体作恶的事件也并非一次两次发生。但模型确切代表了这种共识机制的产生。
举个例子,对于一个特定的DAO来说,如若把治理做到机制,必然会对效率产生影响,原因是群体共识的形成本就是一件麻烦的事情,更何况还要投票、统计等进行一系列操作。如果把DAO的治理以AI模型形式体现,所有的数据收集本就来自于DAO内所有人的发言数据,那么输出的决策实际上会更接近于群体共识。
单个模型的群体共识可以按照如上的方案进行训练模型,但对于这些个体来说终究还是孤岛。若是有集体智能系统形成群体AI,在这个系统中每个AI模型之间会相互协同工作,用来解决复杂问题,其实就对共识层面的赋能有了极大的作用。
对于小型集合既可以自主的去搭建生态,也可以和其他集合形成配合集,更加高效低成本的满足超大型的算力或者数据交易。但问题又来了,各个模型数据库之间的现状是完全不信任、防备着其他人的——这正是区块链的天然属性所在:通过去信任化,实现真正分布式的AI机器间安全高效互动。
一个全球性的智能大脑可以使得原本相互独立且功能单一的AI算法模型相互配合,在内部执行复杂的智能算法流程,就可以不断增长的形成分布式群体共识网络。这也是AI对Web3赋能的最大意义所在。
隐私与数据垄断?ZK与机器学习的结合
人类不论是对于AI作恶还是基于对隐私的保护、对数据垄断的畏惧,都要针对性的进行防范。而最核心的问题在于我们并不知道结论是如何得出,同样的,模型的运营者也并不打算对这个问题解惑答疑。而针对于上文中我们提到的全球性智能大脑的结合就更需要解决这个问题,不然没有数据方愿意拿出自己的核心去和别人共享。
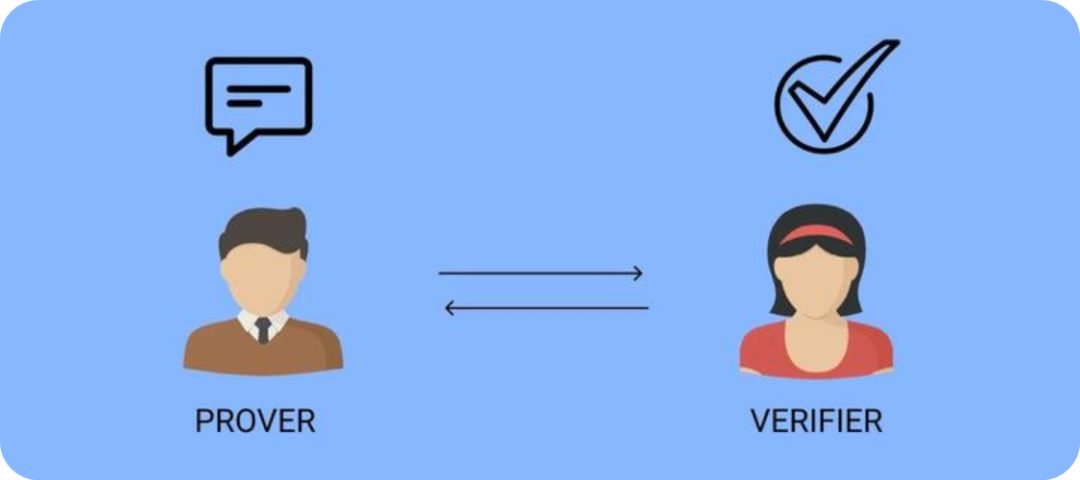
ZKML(Zero Knowledge Machine Learning) 是将零知识证明用于机器学习的技术。零知识证明 (Zero-Knowledge Proofs,ZKP),即证明者(prover)有可能在不透露具体数据的情况下让验证者(verifier)相信数据的真实性。
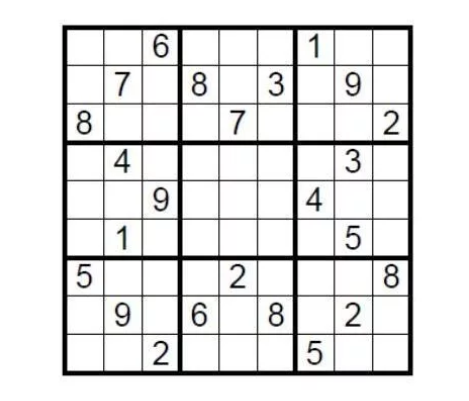
以理论案例为引。有一个9×9的标准数独,完成条件是需要在九个九宫格里,填入1到9的数字,让每个数字在每个行、列及九宫格里都只能出现一次。那么布置这道谜题的人如何在不泄露谜底的情况下向挑战者证明该数独有解呢?
关于【ZKML与分布式算力:AI与Web3的潜在治理叙事】的延伸阅读
知名交易员Ansem年初关注的项目最新进展如何?
加密交易员Ansem因抓住百倍币而闻名,2024年初在社交媒体上列举了13个认为会在2024年表现良好的项目,包括Monad、Dymension、io.net、Anoma、Sovereign和Oh Baby Games等。其中,Anoma是一个类似于EVM的资源机器,Sovereign是一个可在任何区块链上运行的生态系统,Oh Baby Games是一个加密游戏平台,Treeverse是一款基于开放世界、奇幻和科幻的MMORPG,Nillion是一个使用盲计算的L1,Lagrange是一种zk协处理协议,Ritual是一家dApp,可以在链上集成AI模型,Gensyn是一个去中心化计算网络,peaq是为Polkadot上的物联网提供支持的DePin区块链,Colony是一款AI驱动的Web3生存模拟游戏。目前,这些项目都已完成融资,并有不错的表现。
火星财经加密周报 | 5月17日
产业Spectral更新2024年路线图,计划推出新的AI代理和工具,与其他公司合作开发特定用例的代理。iFinex与萨尔瓦多达成合作协议,为数字资产和证券建立监管框架。DFINITY公布最新路线图,重点发展计算平台、去中心化AI、隐私等九个领域。CME计划推出比特币现货交易,推动华尔街进入数字资产行业。KIP Protocol旨在通过KnowledgeFi实现知识变现和劳动有所得,是一种新兴的基建赛道。创始人在香港演讲中强调比特币的强大和其他加密货币的脆弱,提出建设一个社交、博彩和娱乐生态的目标,希望看到更多人的创新和建设,让比特币得到更广泛的认可和使用。
只需要在填充处用答案盖住,然后随机让挑战者抽取几行或者几列,把所有的数字打乱顺序然后验证是否都是一到九即可。这就是一个简单的零知识证明体现。
零知识证明技术具有完备性,正确性和零知识性三个特点,即证明了结论又不需要透露任何细节。其技术来源更是可以体现简约性,在同态加密的背景下,验证难度要远远低于生成证明难度。
机器学习(Machine Learning)则是使用算法和模型来让计算机系统从数据中学习和改进。通过自动化的方式从经验中学习,可以使系统根据数据和模型自动进行预测、分类、聚类和优化等任务。
机器学习的核心在于构建模型,这些模型可以从数据中学习并自动进行预测和决策。而这些模型的搭建构造通常需要三个关键要素:数据集、算法和模型评估。数据集是机器学习的基础,包含了用于训练和测试机器学习模型的数据样本。算法是机器学习模型的核心,定义了模型如何从数据中学习和预测。模型评估是机器学习的重要环节,用于评估模型的性能和准确性,并决定是否需要对模型进行优化和改进。
 在传统的机器学习中,数据集通常需要被收集到一个中心化的地方进行训练,这意味着数据所有者必须将数据共享给第三方,这可能会导致数据泄露或隐私泄露的风险。而使用ZKML,数据所有者可以在不泄露数据的情况下,将数据集共享给其他人,这是通过使用零知识证明来实现的。
在传统的机器学习中,数据集通常需要被收集到一个中心化的地方进行训练,这意味着数据所有者必须将数据共享给第三方,这可能会导致数据泄露或隐私泄露的风险。而使用ZKML,数据所有者可以在不泄露数据的情况下,将数据集共享给其他人,这是通过使用零知识证明来实现的。
零知识证明运用于机器学习的赋能,效果应该是可以预见的,这就解决了困扰已久的隐私黑箱和数据垄断问题:项目方是否可以在不泄露用户数据输入或模型具体细节的情况下完成证明和验证,是否可以让每一个集合都能够共享自己的数据或者模型进行作用而不会泄露隐私数据?当然,目前的技术还早,实践肯定会有很多的问题存在,这并不妨碍我们畅想,并且已经有许多团队在进行开发。
这种状况会不会带来小型数据库对大型数据库的白嫖呢?当你考虑到治理问题的时候,就又回到我们Web3的思维中了,Crypto的精髓在于治理。不论是通过大量的运用或者是共享都应该获得应有的激励。不论是通过原有的Pow、PoS机制还是最新出现的各种PoR(声誉证明机制),都是在为激励效果提供保证。
 分布式算力:谎言与现实交织的创新叙事
分布式算力:谎言与现实交织的创新叙事
去中心化算力网络一直是加密圈热门提到的一个场景,毕竟AI大模型需要的算力惊人,而中心化的算力网络不单会造成资源浪费还会形成实质上的垄断——如果比到最后拼的就是GPU的数量,那未免太没有意思了。
去中心化算力网络,实质是将分散在不同地点、不同设备上的计算资源整合起来。大家常提的主要优势都有:提供分布式计算能力、解决隐私问题、增强人工智能模型的可信度和可靠性、支持各种应用场景下的快速部署和运行,以及提供去中心化的数据存储和管理方案。没错,通过去中心化算力,任何人都可以运行AI模型,并在来自全球用户的真实链上数据集上进行测试,这样就可以享受到更加灵活、高效、低成本的计算服务。
同时,去中心化算力可以通过创建一个强大的框架来解决隐私问题,保护用户数据的安全和隐私。并且提供透明、可验证的计算过程,增强人工智能模型的可信度和可靠性,为各种应用场景下的快速部署和运行提供灵活、可扩展的计算资源。
我们从一套完整的中心化算力流程来看模型训练,步骤通常会分为:数据准备、数据分割、设备间数据传输、并行训练、梯度聚合、参数更新、同步,再到重复训练。在这个过程当中,即便是中心化机房使用高性能的计算设备集群,通过高速网络连接共享计算任务,高昂的通信成本也成为了去中心化算力网络的最大限制之一。
因此,尽管去中心化算力网络具有很多优势和潜力,但依照目前的通信成本和实际运行难度来看发展道路仍然曲折。在实践中,实现去中心化算力网络需要克服很多实际的技术问题,不论是如何确保节点的可靠性和安全性、如何有效地管理和调度分散的计算资源,还是如何实现高效的数据传输和通信等等,恐怕都是实际面临的大问题。
尾:留给理想主义者的期待
回归当商业现实之中,AI与Web3深度结合的叙事看上去如此美好,但资本与用户却更多地用实际行动告诉我们这注定是场异常艰难的创新之旅,除非项目方能像OpenAI一样,在自身强大的同时抱住一个强有力的金主,否则深不见底的研发费用与尚不清晰的商业模式将把我们彻底击碎。
无论是AI还是Web3,现在都处于极为早期的发展阶段,就如同上世纪末的互联网泡沫,一直到近十年之后才正式迎来真正的黄金时期。麦卡锡曾幻想在一个假期之内设计出具有人类智力的人工智能,但直到近七十年后我们才真正迈开人工智能的关键一步。
Web3+AI也同样如此,我们已经确定了前进方向的正确性,剩下的便交给时间。
当时间的潮水逐渐褪去,那些屹立不倒的人和物,便是我们由科幻通向现实的基石。
免责声明:本文仅代表作者个人观点,不代表链观CHAINLOOK立场,不承担法律责任。文章及观点也不构成投资意见。请用户理性看待市场风险,以及遵守所在国家和地区的相关法律法规。
图文来源:Go2Mars Research,如有侵权请联系删除。转载或引用请注明文章出处!
