StarkNet:发布性能路线图,为改进TPS做好准备
只有从全节点的角度考虑,我们才能看到Validity Rollup所提供的真正力量。

原文标题:StarkNet Performance Roadmap
原文来源:medium
原文作者:StarkWare
编译:Yovnne,MarsBit
概要
●L2不受与 L1 相同的吞吐量限制。这为 L2 Validity Rollup带来更高的TPS。
●StarkNet 性能路线图解决了系统中的一个关键元素:定序器。
●我们在此展示性能改进的路线图:
定序器并行化
Cairo-VM 的新 Rust 实现
Rust中的定序器重新实现
● 验证者,可以处理比现在更多的事情。
介绍
大约一年前,StarkNet在主网发布。一开始,我们主要集中构建StarkNet功能性。目前,我们将重点转移至通过一系列步骤提高性能,而这将有助于增强StarkNet体验。
在这篇文章中,我们将解释为什么广泛的优化只适用于Validity Rollup,并分享我们在 StarkNet 上实施这些步骤的计划。其中一些步骤已经在 StarkNet Alpha 0.10.2 中实现,该版本于测试网( 11 月 16 日上线)和主网(11月28日上线)发布。但在我们讨论解决方案之前,让我们回顾一下区块受限问题及其原因。
区块空间限制:Validity Rollup 与 L1
在保持出块时间不变的情况下,提高区块链可扩展性和 TPS 的一种潜在方法是解决区块限制(在Gas/大小方面)。这将需要区块生产者(L1 上的验证器,L2 上的排序器)付出更多努力,需要更有效地实施这些组件。为此,我们现在将重点转移到 StarkNet 定序器优化上,我们将在以下部分中对此进行更详细的描述。
这里自然而然会出现一个问题。为什么定序器优化仅限于Validity Rollup,也就是说,为什么我们不能在 L1 上实现相同的改进并完全避免Validity Rollup的复杂性?在下一部分,我们将解释两者之间存在的根本区别,允许对不适用于 L1 的 L2 进行广泛的优化。
为什么 L1 吞吐量有限?
不幸的是,解除对 L1 的区块限制会遇到一个重大陷阱。通过提高区块链的增长率,我们也增加了对全节点的需求,他们试图跟上最新的状态。由于 L1 全节点必须重新执行所有历史记录,区块区间的大幅增加(就Gas而言)会给它们带来巨大压力,再次导致较弱的机器(节点)退出系统并将保留运行全节点的能力归向足够大的实体。最终,用户将无法自己验证状态,以及以去信任方式参与网络。
这让我们明白 L1 吞吐量应该受到限制,以维护一个真正去中心化和安全的系统。
为什么相同的问题不会影响Validity Rollup?
只有从全节点的角度考虑,我们才能看到Validity Rollup所提供的真正力量。L1 全节点需要重新执行整个交易历史,以确保当前状态的正确性。StarkNet 节点只需要验证 STARK 证明,而该验证所占用的计算资源量呈指数级下降。特别是,从头开始同步不一定涉及执行;一个节点可能会从其对等节点接收到当前状态的转储,并且只能通过 STARK 证明来验证该状态是否有效。这使我们能够在不增加全节点要求的情况下增加网络的吞吐量。
因此,我们得出结论,L2 定序器会对整个优化范围带来影响,但这在 L1 上是不可能的。
未来的性能路线图
在接下来的部分中,我们将讨论目前哪些计划用于 StarkNet 定序器。
定序器并行化
我们路线图的第一步是将并行化引入交易执行。这是在昨天在主网上发布的 StarkNet alpha 0.10.2 中引入的。我们现在深入了解什么是并行化(这是半技术部分,要继续关注路线图,请跳至下一节)。
关于【StarkNet:发布性能路线图,为改进TPS做好准备】的延伸阅读
BTC L2研究报告: L2整体的市值仅有BTC市值的0.1%?盘点时下主流解决方案
本文探讨了比特币生态系统的发展和扩容方案的重要性,以及铭文、BRC-20代币、符文等对比特币交易费用的影响。比特币的可扩展性问题变得更加紧迫,本文将深入探讨Rollup、侧链和状态通道等解决方案。Taproot升级和BitVM技术是比特币扩容的两大进展,可以提高隐私性、可扩展性和可组合性。RGB和Stacks协议是扩展比特币功能的两种方式,BounceBit则是一个比特币扩容协议。它们都有各自的优势和挑战,但都旨在提高比特币的可扩展性和功能。
用原生L2代币来支付交易手续费
本文介绍了L2代币支付交易手续费的优缺点,包括增加代币用途、影响使用体验和L2之间的互通性。StarkNet是第一个计划使用STRK支付手续费的L2,引入第三方Oracle来报价汇率。使用者只能指定手续费并相信Sequencer,而Oracle适合在L1的Force Inclusion机制中避免超额手续费和滥用低廉手续费。L2可以规定使用L2代币支付手续费,但使用者需要同时支付L1和L2代币,影响使用体验。
那么“交易并行化”是什么意思?并行执行一个交易块是不可能的,因为不同的交易可能是相互依赖的。这在以下示例中进行了说明。一个包含来自同一用户的三笔交易的区块:
●交易A:将USDC换成ETH
●交易 B:为 NFT 支付 ETH
●交易C:USDT换BTC
显然,Tx A 必须在 Tx B 之前发生,但 Tx C 完全独立于两者并且可以并行执行。如果每笔交易需要 1 秒来执行,那么通过引入并行化,出块时间可以从 3 秒减少到 2 秒。
问题的症结在于我们事先并不知道交易的依赖关系。实际上,只有当我们从示例中执行事务 B 时,我们才能看到它依赖于事务 A 所做的更改。进一步说,这一依赖性源于事务 B 从事务 A 写入的存储单元中读取这一事实。我们可以将交易画成一个依赖图,其中存在从交易 A 执行至交易 B ,当且仅当 A 写入一个由 B 读取的存储单元,因此必须在 B 之前执行。下图显示了依赖图的示例:
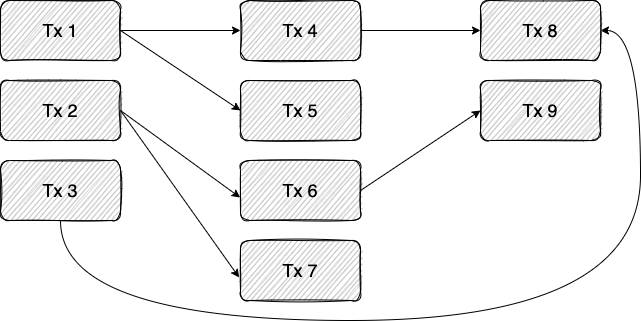 在上面的示例中,每一列都可以并行执行,这是最佳安排(天真地,我们会顺序执行事务 1-9)。
在上面的示例中,每一列都可以并行执行,这是最佳安排(天真地,我们会顺序执行事务 1-9)。
为克服事先不知道依赖图的事实,我们本着 Aptos Labs 开发的BLOCK-STM的精神,将optimistic并行化引入到 StarkNet 定序器中。在该范式下,我们乐观地尝试并行运行事务并在发现冲突时重新执行。例如,我们可以并行执行图 1 中的交易 1-4,之后才发现 Tx4 依赖于 Tx1。因此,它的执行是无用的(我们相对于运行 Tx1 所针对的相同状态运行它,而我们应该针对应用 Tx1 所产生的状态运行它)。在这种情况下,我们将重新执行 Tx4。https://malkhi.com/posts/2022/04/block-stm/
请注意,我们可以在optimistic并行化之上添加许多优化。例如,与其天真地等待每次执行结束,我们转而可以在发现使它无效的依赖项时中止执行。
另一个例子是优化重新执行哪些交易的选择。假设包含图 1 中所有事务的块被送入具有五个 CPU 内核的定序器。首先,我们尝试并行执行交易 1-5。如果完成顺序是Tx2,Tx3,Tx4,Tx1,最后是Tx5,那么只有在Tx4已经执行完之后,我们才会发现依赖Tx1→Tx4——说明应该重新执行。天真地,我们可能也想重新执行 Tx5,因为考虑到 Tx4 的新执行,它的行为可能会有所不同。然而,我们可以遍历由执行已经终止的交易构建的依赖图,只重新执行依赖于 Tx4 的交易,而不是仅仅重新执行现在无效的 Tx4 之后的所有交易。
Cairo-VM 的新 Rust 实现
StarkNet 中的智能合约是在 Cairo 中编写的,并在 Cairo-VM 中执行,该规范出现在Cairo白皮书中。目前,定序器正在使用 Cairo-VM 的python 实现。为优化 VM 实现性能,我们发起使用 Rust 重写 VM 的工作。感谢 Lambdaclass 的出色工作,他们现在是 StarkNet 生态系统中一个非常宝贵的团队,这项工作很快就会取得成果。
VM 的 rust 实现,cairo-rs,现在可以执行原生 Cairo 代码。下一步是处理智能合约的执行,以及与 pythonic 定序器的集成。一旦与 cairo-rs 集成,定序器的性能有望显着提高。
Rust 中的定序器重新实现
我们从 python 到 rust 以提高性能的转变不仅限于 Cairo VM。除了上述改进之外,我们还计划用 Rust 从头开始,重写定序器。除了 Rust 的先天优势之外,这还为序列器的其他优化提供了想象空间。举几个例子,我们可以享受 cairo-rs 的好处,而无需为 python-rust 通信支付费用,我们可以完全重新设计状态的存储和访问方式。
证明者
在整篇文章中,我们都没有提到Validity Rollup中最知名的元素——证明者。可以想象,作为可以说是架构中最复杂的组件,它应该是瓶颈,因此也是优化的重点。有趣的是,现在 StarkNet 的瓶颈是更“标准”的组件。今天,特别是对于递归证明,我们可以将比测试网/主网上的当前流量更多的交易放入证明中。事实上,目前,StarkNet 区块与 StarkEx 交易一起得到证明,后者有时会产生数十万 NFT 铸造交易。
总结
并行化、Rust 等——为即将到来的 StarkNet 版本中改进的 TPS 做好准备。
免责声明:本文仅代表作者个人观点,不代表链观CHAINLOOK立场,不承担法律责任。文章及观点也不构成投资意见。请用户理性看待市场风险,以及遵守所在国家和地区的相关法律法规。
图文来源:MarsBit,如有侵权请联系删除。转载或引用请注明文章出处!
