长推:简单理解Rollup交易的生命周期
中心化是区块链世界中首先要避免的事情。

原文作者:Shiva
原文来源:Twitter
编译:Yvonne,MarsBit
释放rollup交易的生命周期:
目前状态(中心化排序器)vs 未来(模块化一切)
首先,让我们来看看当前中心化rollup情况:
当你在rollup dApp上执行操作并单击钱包上的“签名”时,交易旅程就开始了。
钱包就是你的界面。
这是你与区块链网络互动的方式。
在这背后,钱包与rollup RPC节点交互以检查rollup的状态。
如果把区块链比作一所房子,那么RPC节点就像通往那所房子的门。
这是任何人都可以阅读区块链分类帐的方式。
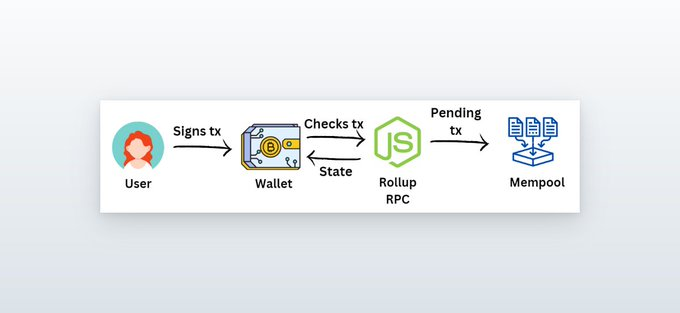
rollup RPC将tx(作为“pending tx”)发送到称为内存池或内存池的交易储存库。
内存池是一个由节点组成的p2p网络,可共享交易数据——但是这里的交易是无序的。
现在,中心化rollup运营商开始发挥作用。
该运营商(或“排序器”)执行多个任务:
1. 对txs进行排序并创建一个块
2. 它向用户发送一个“软确认”,说明tx已经包含在L2块中,最终也将包含在L1块中
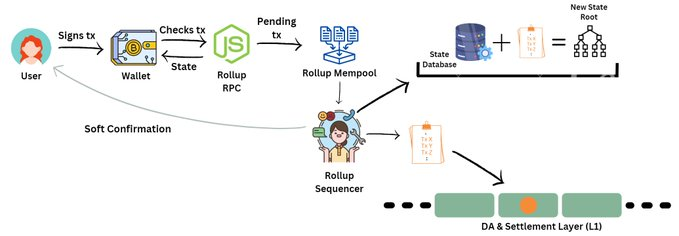
3.压缩交易批次并将其发布到数据处理层-(为了简单起见,假设它与结算层(L1)相同,例如以太坊)
4. 执行交易块以获得一个新的状态根,以前的状态根+新的tx数据=新的状态根。
然后在更新rollup状态的网络的各个节点之间传播新的状态根。
基础层以太坊运行rollup的轻客户端,该客户端也接收新状态。
以太坊上的rollup智能合约还验证任何有效性证明(在zkru的情况下)或欺诈证明(在oru的情况下),然后更新L1数据库中的rollup状态。
至此,就完成了。
交易旅程完成了。
说得通吗?
到这里为止很简单。
中心化运营商负责所有的事情,这个过程看起来很简单。
但中心化是我们在区块链中首先要避免的事情!
以下是中心化rollup排序器不够理想的3个原因:
-审查交易
-实行垄断定价
- 在用户之前抢先交易,生成MEV
此外,孤立的rollup会分散不同rollup之间的流动性。
怎么解决?
关于【长推:简单理解Rollup交易的生命周期】的延伸阅读
Coin Metrics:分析以太坊 Blob 与 EIP-4844 的影响
自3月13日起,多个Layer-2解决方案采用blob交易,超过950,000个blob已发布到以太坊,降低了操作成本。EIP-4844升级提高了L2的可伸缩性和降低交易成本,每天约有10,000个blob发布。blob被设计为18天后过期,防止永久存储膨胀。随着rollups使用blob发布大量数据,blob空间利用率将增加。blob费用根据需求动态调整,4月份因铭文blob激增而增加,但随后又降低。Blob的采用是EIP-4844降低数据存储开销和增强L2可伸缩性的积极信号。然而,跨资产、流动性和用户体验碎片化等挑战仍需解决。随着更多L2利用blob,拥塞可能会再次出现。
Stacks Nakamoto 升级,BTC生态的文艺复兴
Stacks是一个跨链共识区块链,旨在将智能合约功能移植到比特币网络中。其共识机制为转移证明,通过燃烧比特币来参与挖矿。Stacks 2.0主网已推出,获得美国证券交易委员会批准的代币销售。Stacks 3.0升级解决了安全性、性能和可扩展性等问题,引入签名者角色,提高链的可扩展性。Nakamoto升级解决了MEV问题,提高了挖矿过程的公平性和稳定性。升级将在4月22日开始,提高Stacks区块链的透明度和信任度。
模块化!
在以太坊生态系统正在走向的模块化世界中,中心化rollup运营商的执行职责将被抽象出来,并由单独的层执行。
在这时,交易生命周期会发生如下变化:
旅程再次开始,用户通过钱包签名交易。
钱包使用rollup RPC检查状态,并将“pending”tx发送到内存池。
但是,它不是将tx发送到特定于rollup的内存池,而是将tx发送到*共享sequencer*内存池。
共享的排序器内存池接收来自几个不同rollup的交易。
称为搜索者的实体跟踪该内存池以搜索任何MEV机会。
搜索器通常是执行以下任务的重型全节点:
-提取一些交易
-添加自己的交易
-创建一个交易包来提取MEV
-把交易包发送给“builder”
-为他们的bundle出价,由builder选择
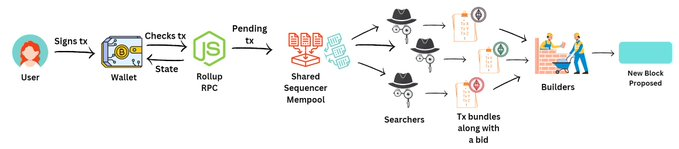
构建器也是繁重的完整节点,它从出价最高的搜索器那里获取bundle。
除了内存池中的其他tx外,它们还将bundle包含到一个块中,并将该块“提议”给共享排序器。
共享序列器现在执行以下操作:
1. 选择最好的块(最高出价/遵循所有分组的标准等)。
2. 向所有rollup用户发送包含交易的软确认
3. 将有序的数据块写入数据处理层
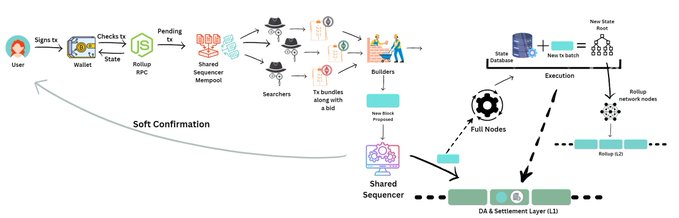
rollup的完整节点:
-从共享排序器或基础层检索块;
-根据他们的fork选择规则进行检查
—从其他rollup中过滤掉交易,并且使用STF(状态转换函数)将生成的交易子集应用到其先前的状态。
这将生成rollup的新状态,然后将其传递给轻客户端。
同时,在L1智能合约上的流程是相同的:
验证有效性证明或欺诈证明并更新数据库。
这就是全部!
由于共享排序器不参与执行,它可以是“无状态的”——这使得它们很容易实现去中心化!
而且由于多个rollup可以共享一个去中心化的排序器,这也提高了它们之间的互操作性。
@AstriaOrg和@EspressoSys是两个优秀的团队,为模块化的未来构建共享排序器!Flashbots正在打造一个“去中心化的构建器”——“SUAVE”。我希望这有助于你理解最近关于排序器、提议器、构建器的讨论。
免责声明:本文仅代表作者个人观点,不代表链观CHAINLOOK立场,不承担法律责任。文章及观点也不构成投资意见。请用户理性看待市场风险,以及遵守所在国家和地区的相关法律法规。
图文来源:MarsBit,如有侵权请联系删除。转载或引用请注明文章出处!
